SECOND LIFE
ABSTRACT:
This research focuses on one of the main problems in the AEC industry: the huge amount of waste it produces.
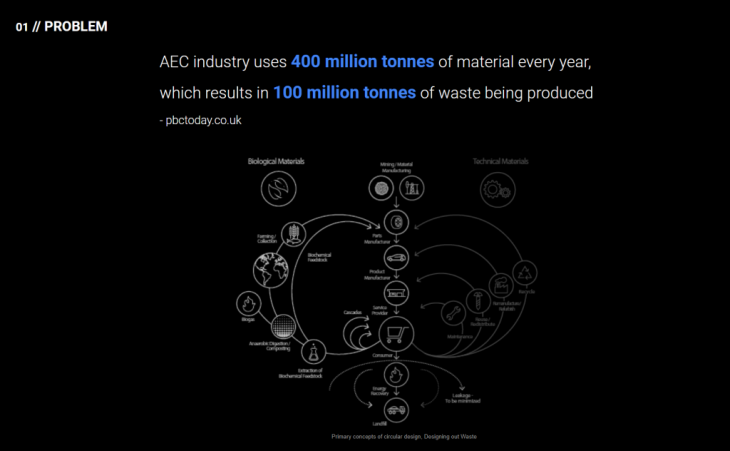

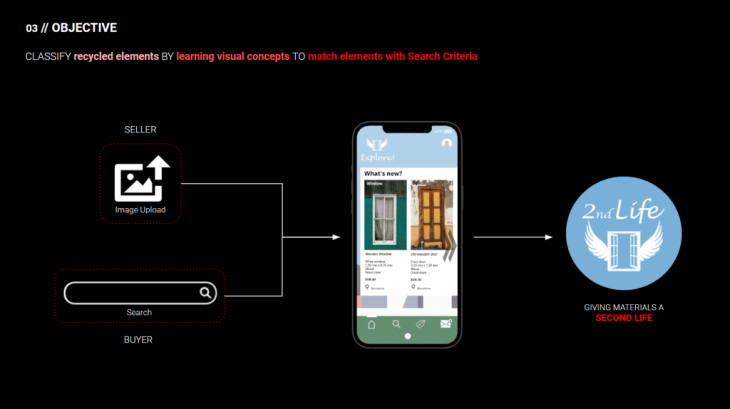
As a contribution in the way to solve it, this tool classifies recycled elements which can have a second life, by learning visual concepts to finally match them with the search criteria that the user specifies.
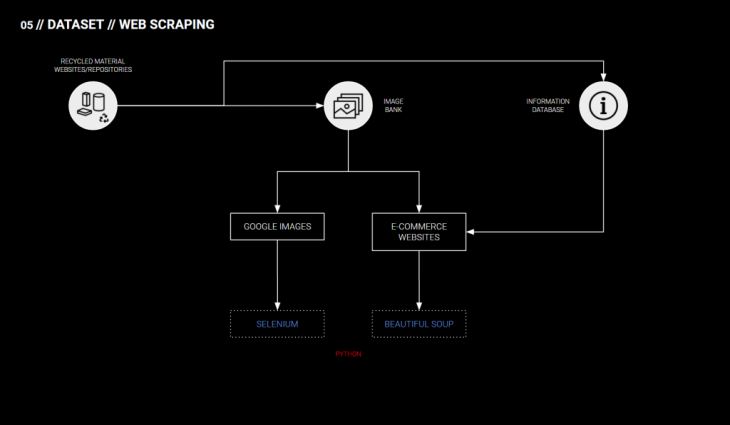
WEB SCRAPING:
For creating our datasets, we looked at how to scrape images from Google. We created our own image bank using specific search keywords, which would then be used for tagging. For scraping the images from Google Images, we used the Selenium library.
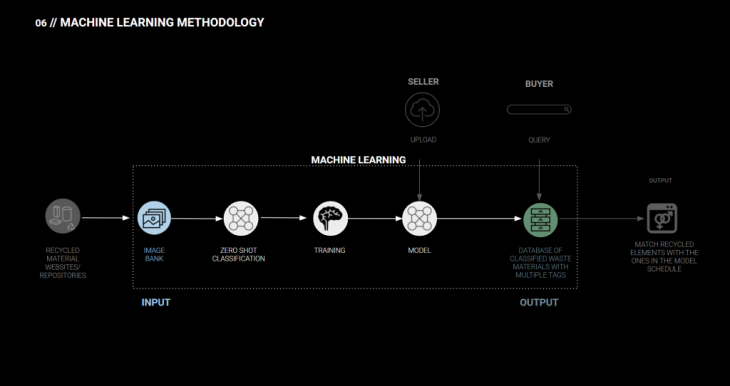
MACHINE LEARNING MODELS:
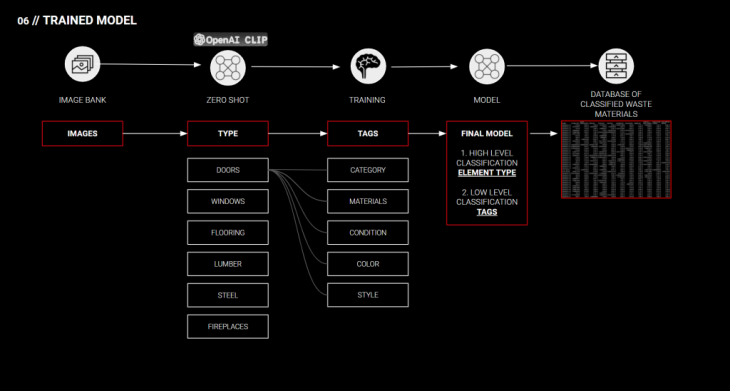
The input for our machine learning models, then, is an image bank which is obtained from the image scraping techniques discussed earlier. Having a dataset ready, we are classifying the images and producing the output of a database with multiple tags per given element.
We are using the CLIP model developed by OpenAI. Clip is a neural network trained on hundreds of millions of image text pairs. Given a couple of possible text captions, clip will return probabilities for each class. Clip can predict in a zero shot manner, which means it can be accurate on classes that it has never seen in a training.
CLIP model can be described as a bridge between computer vision and natural language processing. It includes image and text encoders that compute the representation of both image and text. For each image, it calculates the representation and checks how similar it is to each text class representation to predict the best fit.
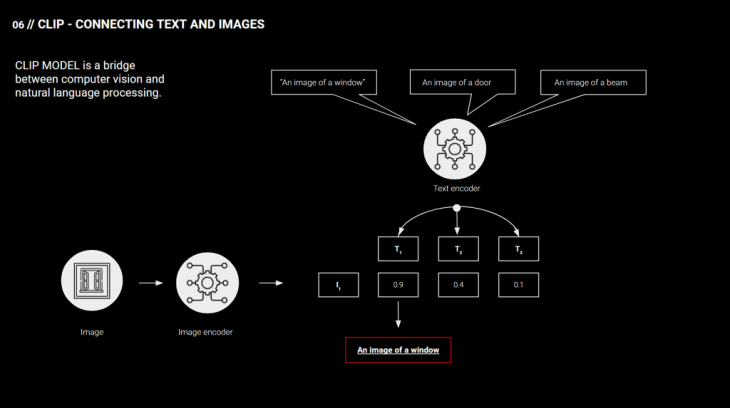
At the beginning of trying CLIP on our images we realized that CLIP performs very well given a task of recognizing whether the image contains a door, window or beam. Seeing this, we wanted to take the classification a step further, and tag the element with more subtle features like style, condition, color, etc. As the zero shot classification did not perform well on all the tags we wanted to recognize, we decided to fine-tune the model to be able to recognize specific features. Each element would have a specific list of tags.
Our training steps were first to create a dataset with images and labels, then set up training hyperparameters, then perform training and at the end validate on the test set.
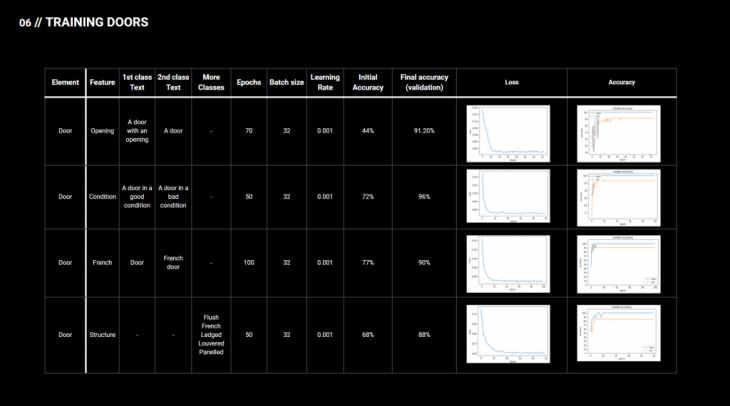
We tried 4 different datasets, first of them was the door. The following images contain the classes that we used for each training. In multiple cases the zero shot capabilities were already good, and on average we were able to increase the accuracy by around 20%. There were some cases in our training that we were able to improve the accuracy from 30 or 40 percent to around 90.

Image below contains a glance into our training log with the number of epochs, batch size, learning rate as the initial and final accuracies.
Other classes that we ran training for were flooring, windows and lumber.



As a result we end up with the model that would first recognize the type of element and then based on the type could assign tags specific to this element. This would let us create a database of our inventory with all available elements and probabilities for each class.

Now, looking at the results from the ML methodology in the context of our application – when the seller uploads the image, it will be classified with the model and the result will be saved in the database. When the buyer searches for a specific element, a query is sent to the database to find the most suitable element.
One extra feature that we added in the end of the process in the methodology for interaction with the buyer and recommending elements based on user selection.
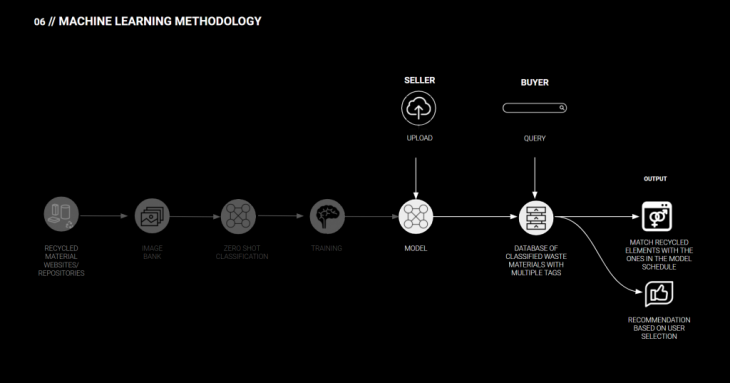
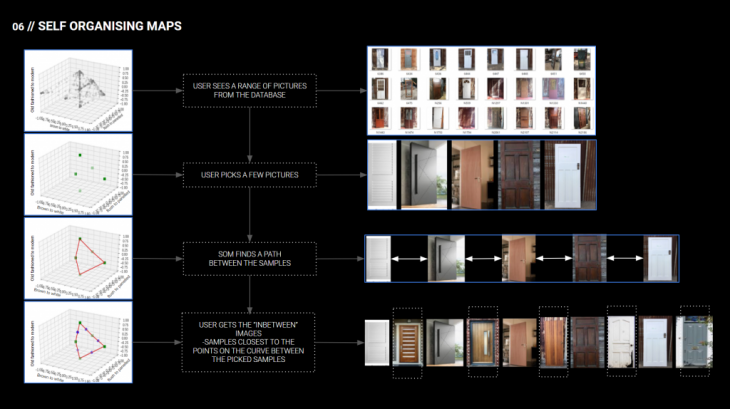
We have the database of available materials and a subset of it would be presented to the user. The user will then pick a couple of pictures. Next step is using unsupervised learning techniques such as self organizing maps to find similar or in between values, so that the end user could be recommended with more options.

This is a specific example where we used miniSOM solving the traveling salesman problem.
Out of the door database we picked 5 images, SOM found the best path connecting them. Then we found in between points on the paths and together with the corresponding closest images to obtain the in between images that could be recommended to the buyer.
WEB APP:
To put these things together into a web were the user could interact, upload its images and use our tool, we developed a web application using flask. This web app would connect the user with the pickle model we trained and saved to classify the image he uploaded or it would match with the database according with the search criteria he stablished.

As part of an open source project, which anyone could continue developing or use, we shared these developments and files in a Github repository, which you can find here: Second Life repository
In this repository you can find instructions on how to use this tool for further development.

As we wanted this tool to be accesible for everyone, we also thought about how the interface of a phone app would look like, and we designed the mock up for this phone application, which could afterwards be developed.

SECOND LIFE is a project of IAAC, Institute for Advanced Architecture of Catalonia developed at Master in Advanced Computation for Architecture & Design in 2020/21 by
Students: Sumer Matharu, Aleksandra Jastrz?bska, Jonathan Hernández López and Jaime Cordero Cerrillo
Faculty: Angelos Chronis and Lea Khairallah