ROBOTIC SCANNING FOR ARCHITECTURAL DATA EXTRACTION, ANALYSIS AND VALIDATION
VIDEO – ABSTRACT
Robotic Scanning for architectural data extraction, analysis and validation is an experiment in the use of robotic scanning to scan, analyze and extract geometric and contextual site information that would inform architectural decision making.
CONTEXT:
Robotic Scanning is not new technology. It has been used in the precision manufacturing industry for some time now. But its adoption into architecture is fairly recent and full of challenges and possibilities. Among the many challenges it has to overcome 2 stand out as major hurdles. First amongst them is to broaden the parameters from detecting specific data set to a wide range of data types. Given that architecture is a bespoke industry, no two projects will have the same type of data and it becomes imperative in robotic scanning to distinguish this range of data.
The second problem is to try and consolidate the fragmented technology into a seamlessly integrated setup that can allow the conversion of raw data to into a format that readable by an architectural software. With these objectives in mind our first step was to identify the latest technology and setup being used to gather data.
CASE STUDIES:
DOXEL
Doxel is a robotics company based out of Redwood city, California that use robots to map and inspect ongoing construction projects. Doxel robots uses a Lidar and visual scanners to manage construction progress. It tracks construction progress, inspects quality and detect errors onsite to deter and delay of the project.


SCALED ROBOTICS:
Scaled Robotics by Stuart Maggs is a robotics company based out of Barcelona that verifies construction and monitors progress using robots. The robots use a laser scanner to gather precise information from the site.

STRATEGY:
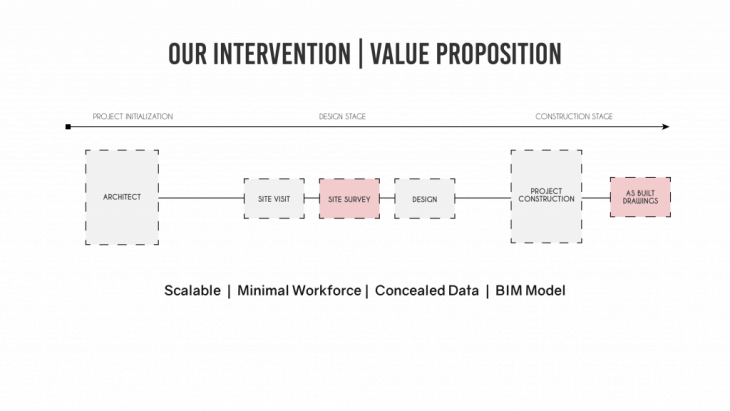
The above mentioned case studies largely utilized robotic scanning in ongoing construction sites but not prior to envisioning of the project such that the data extracted would inform design decisions. An architects workflow during the conception of a project involves site survey / scanning that helps them gather data for the design process. Apart from the conception, robotic scanning can also be utilized to verify if the design is built as per the construction drawings and that generate a set of as built drawings. The use of robotic scanning can improve the data gathered with the use of a minimal workforce.
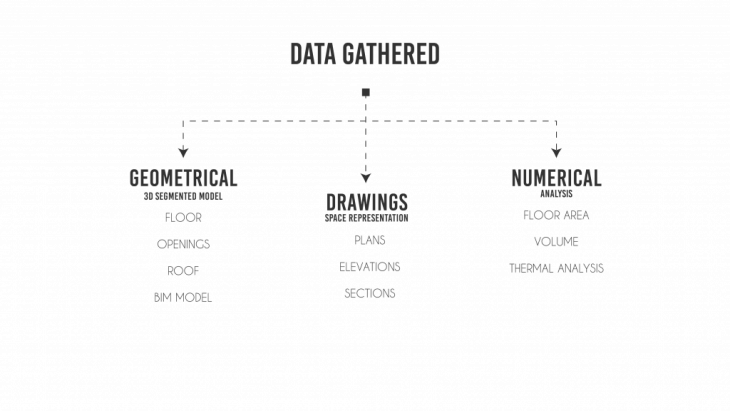
Data required by an architect that informs or assists in the design process.
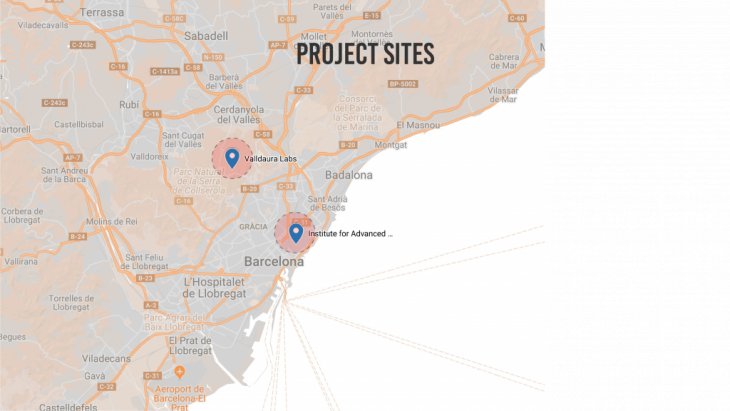
With the above objectives in mind, 2 prospective sites were chosen for our test. The Valldaura campus and Poblenou campus of I.A.A.C.
SITE 1:

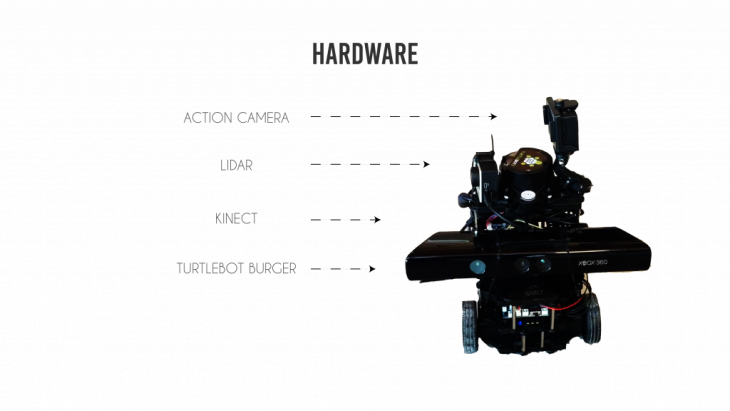
HARDWARE:
The robot used for scanning was the turtlebot 3. It was equipped with the following hardware to assist in the scanning process.
- Action Camera. – to capture HD images
- Lidar – to generate a map
- Kinect – get accurate depth and images.
TEST RUN : The first run comprised of getting a video from which images were clipped but this resulted in the generation of an unreliable point cloud. The second run had images snapped at regular intervals with atleast 50% overlap between images which helped generate a usable point cloud.
The ideal process of gathering data autonomously would involve running a Frontier exploration on the turtlebot to map the space and generate a plan using the Lidar and then defining a pathway for the turtlebot to move through the space such that it captures all the requisite data required to generate a complete point cloud.

POINT CLOUD: The images were processed through Photoscan to generate a point cloud which was used to extract data.


SEGMENTATION:
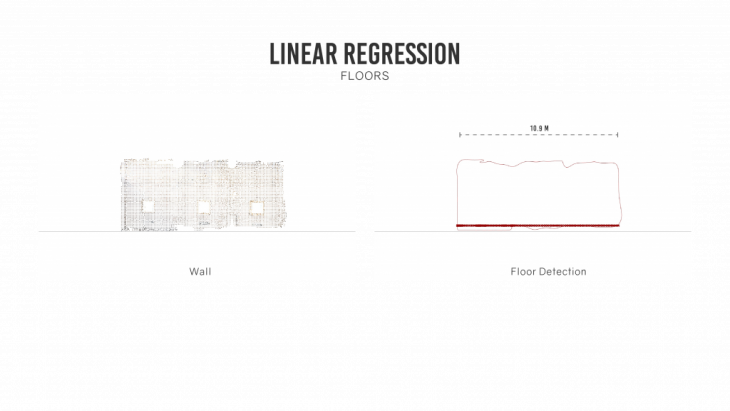
The point cloud by itself lacks scale and consists of many distortions and noise that hinders its direct use into an architectural drawing. The cloud needs to be filtered and processed before usage components are extracted from it. The cloud was first segmented using a region based segmentation to extract planes and surfaces. This helped isolate the walls, floor and the roof that was later processed further to filter out more data.


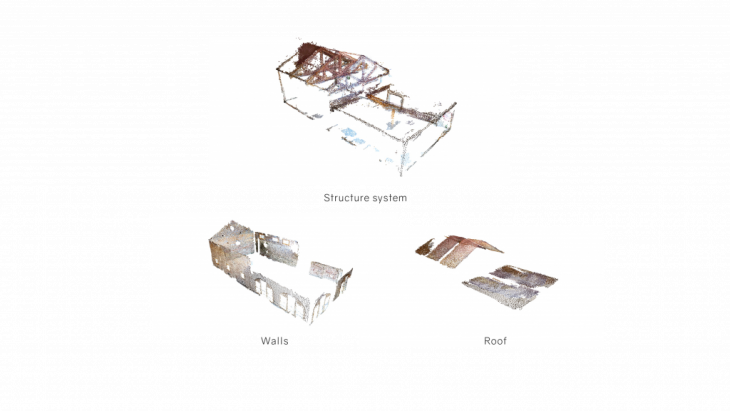
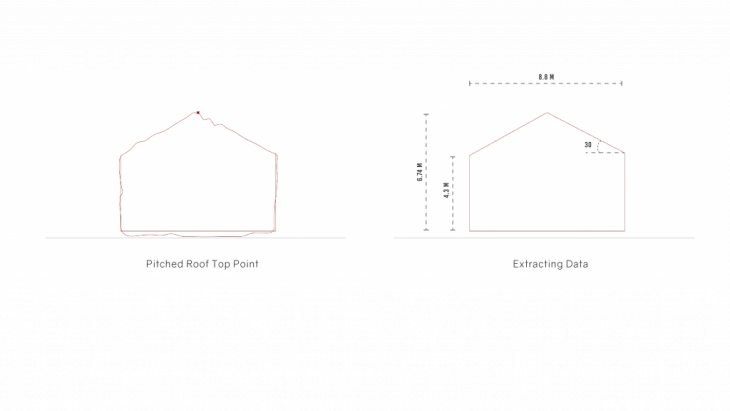
EXTRACTION OF CURVES:
Once the planes a concave hull algorithm was run over it to get the boundary of the point. This helped generate a 2d surface drawing of the points.
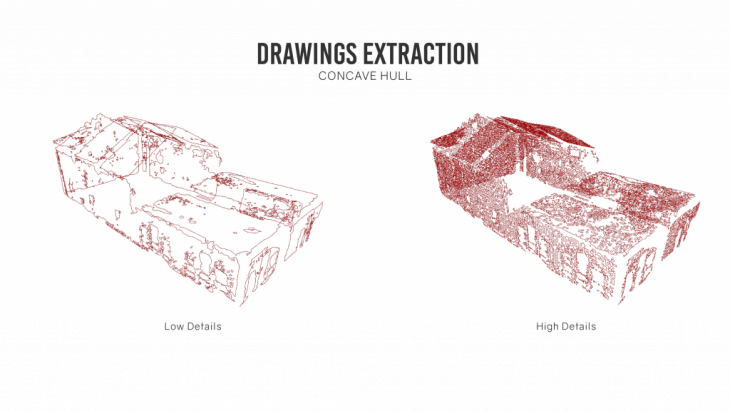

Depending upon the precision of the point cloud it may comprise of noise which needs to be removed to get clean lines of the surface.
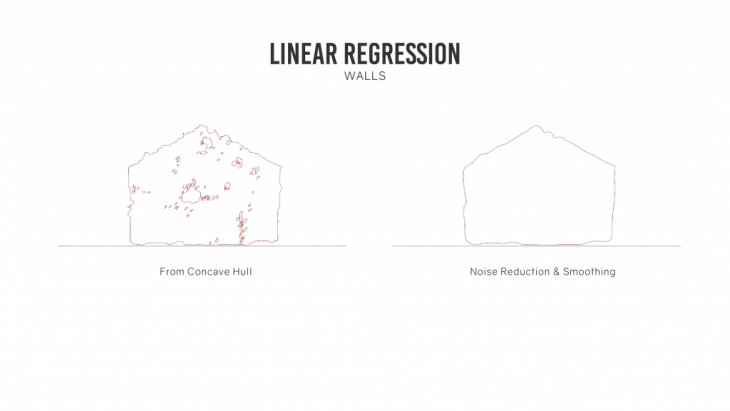
LINEAR REGRESSION:
The curves generated using concave hull could have an irregular boundary due to stray points outside the boundary. To smoothen the curves, we can run a linear regression algorithm to get an average of the position of the points. A simple linear regression was run to get the final curves from the boundary. For a higher accuracy a multivariate linear regression can also be run across the curves.
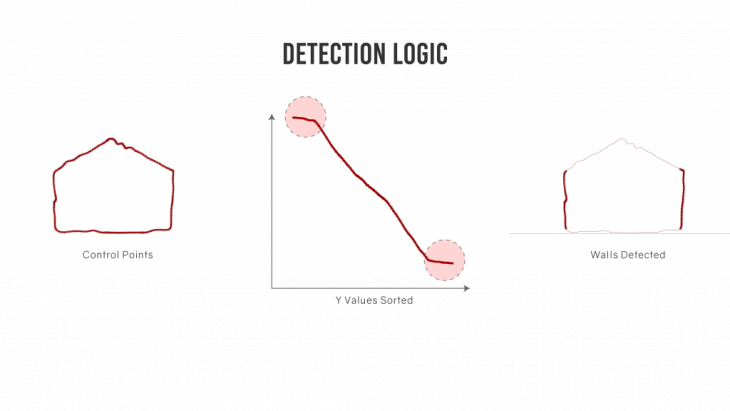
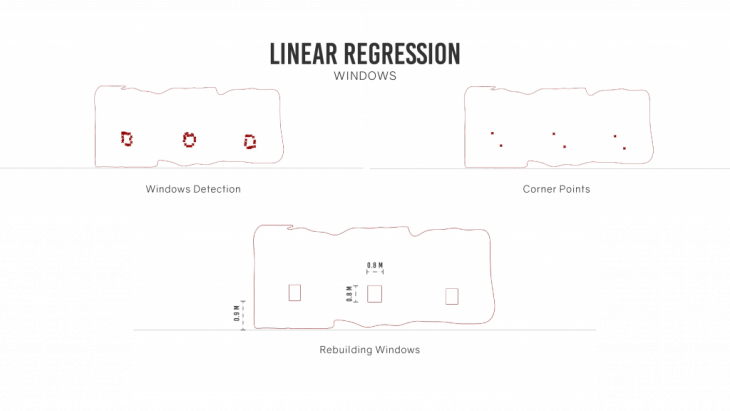
Isolating windows / openings from the points.
The final output gives an outline drawing of the building. These curves comprise of all the geometric data of the building.
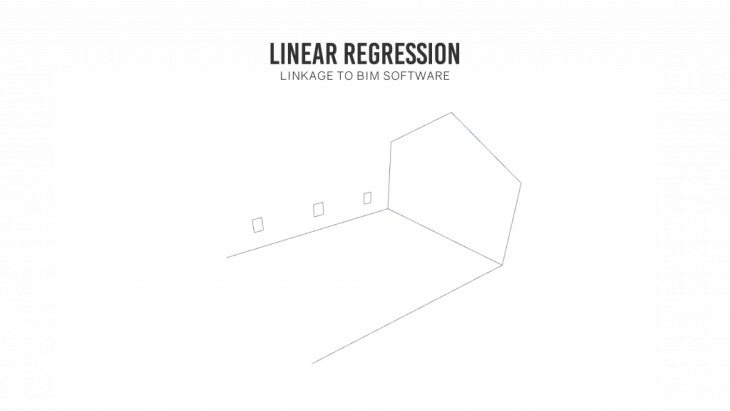
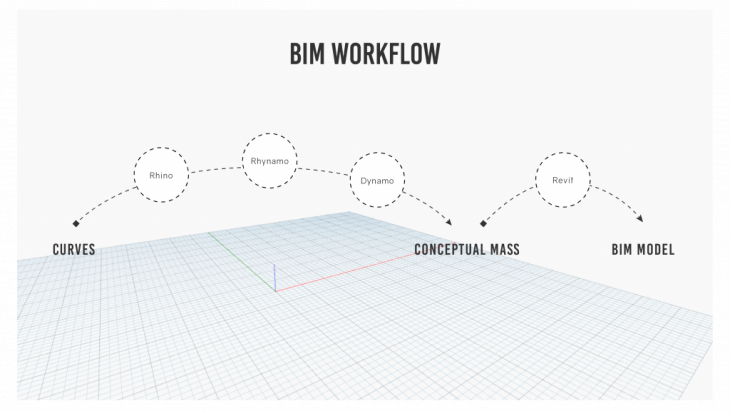
BIM WORKFLOW:
BIM softwares like Revit are the most widely used software for development of architectural models and construction workflows. So any data extracted using robotic scanning needs to be integrated to the BIM workflow if it has to be utilized by architects / consultants.
Among the many workflows available to integrate the curves into revit, we utilized the Rhino – Rhynamo – Dynamo – Revit workflow. This allowed the model to be parsed through Dynamo which has computational capabilities.
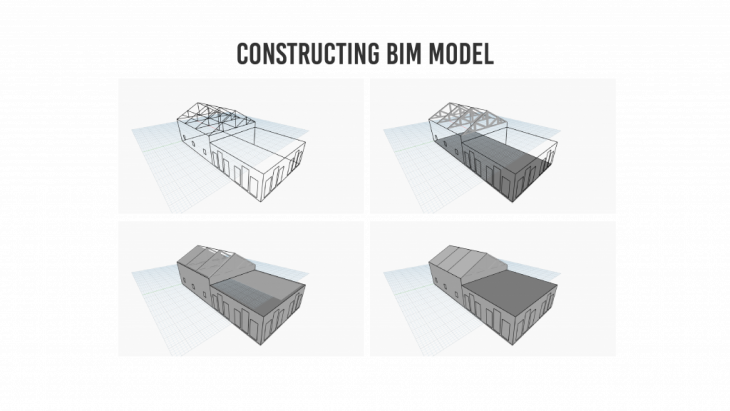
The final model extracted out of the workflow is a fully exploitable BIM model that can be modified or exploited in any manner as required by the user.

SITE 2:
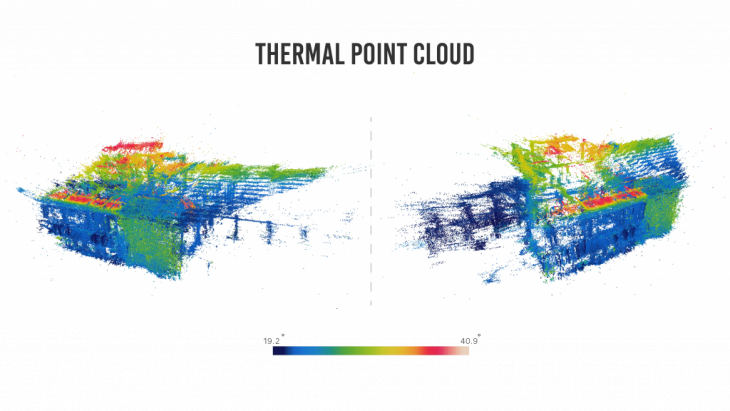
Site 2 was the test site for a data fusion exercise. The test involved gathering thermal data of the building and incorporating it with the point cloud, thus creating a thermal point cloud.

TEST RUN: Collecting images for a thermal point cloud using a FLIR camera. The data required to generate a thermal point cloud involves 2 sets of images, a thermal image and an RGB image of the same viewport.
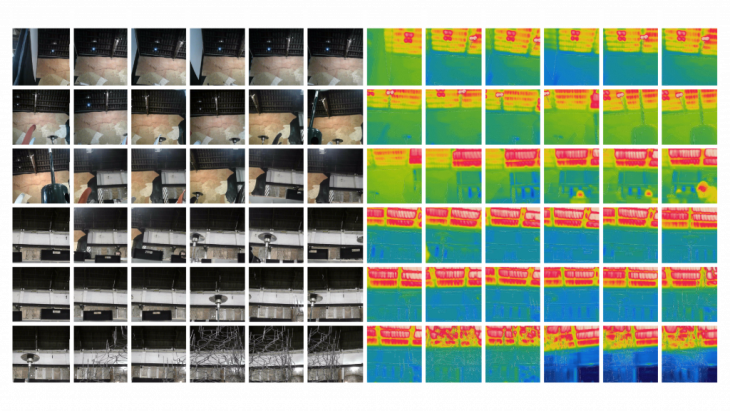
Generating a thermal point cloud requires making a regular point cloud using Colmap and then replacing the images used to make an RGB point cloud by the thermal images. The point cloud generated superimposes the thermal color values on the RGB cloud thus creating a thermal cloud. This kind of data fusion can be done over an array of different data, thereby getting a spatial configuration of the data.


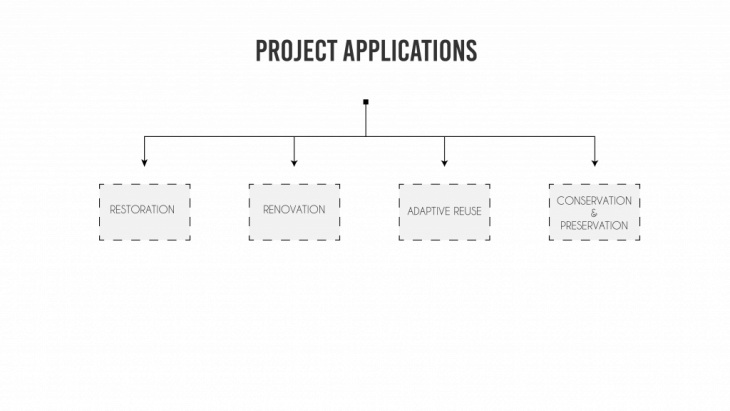
PROJECT APPLICATIONS:
This kind of data can be used for different types of projects which involves gathering of site data.
SERVICES & TARGET CLIENTS:
This type of data is beneficial for a variety of professionals engaged in the architectural / real estate profession.
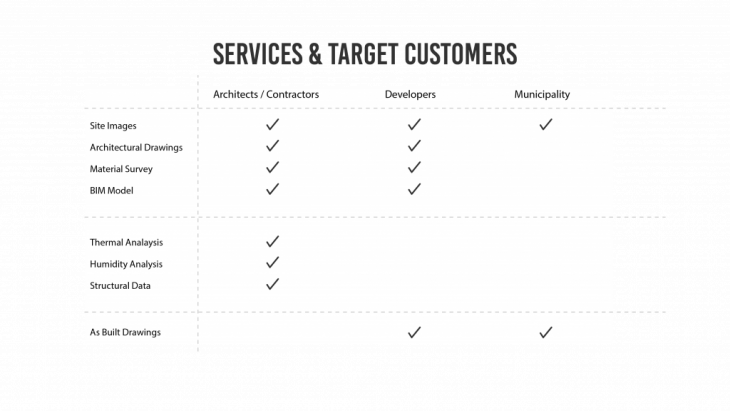
In case of an interior refurbishment project, most of the data required from site can be gathered by robotic scanning. Apart from the below mentioned checklist an additional array of data like thermal data, structural data, illumination data, humidity analysis.

CONCLUSION:
While this process can help generate a BIM model from a poinTcloud scan of a space, in order for it to run autonomously for all spaces, a machine learning algorithm has to be incorporated to detect, analyze and classify all scans and points in the right architectural data set.
BIBLIOGRAPHY + CREDITS :
Adán, A. et al. (2015) ‘Towards the Automatic Scanning of Indoors with Robots’, Sensors. Multidisciplinary Digital Publishing Institute, 15(5), pp. 11551–11574. doi: 10.3390/s150511551.
Bard, J. et al. (2019) ‘Thermally Informed Robotic Topologies: Profile-3D-Printing for the Robotic Construction of Concrete Panels, Thermally Tuned Through High Resolution Surface Geometry’, in Robotic Fabrication in Architecture, Art and Design 2018. Cham: Springer International Publishing, pp. 113–125. doi: 10.1007/978-3-319-92294-2_9.
Bard, J., Bidgoli, A. and Chi, W. W. (2019) ‘Image Classification for Robotic Plastering with Convolutional Neural Network’, in Robotic Fabrication in Architecture, Art and Design 2018. Cham: Springer International Publishing, pp. 3–15. doi: 10.1007/978-3-319-92294-2_1.
Battaglia, C. A., Miller, M. F. and Zivkovic, S. (2019) ‘Sub-Additive 3D Printing of Optimized Double Curved Concrete Lattice Structures’, in Robotic Fabrication in Architecture, Art and Design 2018. Cham: Springer International Publishing, pp. 242–255. doi: 10.1007/978-3-319-92294-2_19.
Biagini, C. et al. (2016) ‘Towards the BIM implementation for historical building restoration sites’, Automation in Construction, 71, pp. 74–86. doi: 10.1016/j.autcon.2016.03.003.
Bruno, S., De Fino, M. and Fatiguso, F. (2018) ‘Historic Building Information Modelling: performance assessment for diagnosis-aided information modelling and management’, Automation in Construction, 86, pp. 256–276. doi: 10.1016/j.autcon.2017.11.009.
Dore, C. and Murphy, M. (2017) ‘Current State of the Art Historic Building Information Modelling’, Conference papers. doi: 10.5194/ispr-archives-XLII-2-W5-185-2017.
Dubor, A. et al. (2019) ‘On-Site Robotics for Sustainable Construction’, in Robotic Fabrication in Architecture, Art and Design 2018. Cham: Springer International Publishing, pp. 390–401. doi: 10.1007/978-3-319-92294-2_30.
Gramegna, T. et al. (2006) ‘Automatic construction of 2D and 3D models during robot inspection’, Industrial Robot: An International Journal. Edited by M. Wilson. Emerald Group Publishing Limited, 33(5), pp. 387–393. doi: 10.1108/01439910610685061.
Hayes, C. and Richie, E. (no date) When to Use Laser Scanning in Building Construction A Guide for General Contractors. Available at:
http://constructrealityxyz.com/test/ebook/LGS_AU_When
to Use Laser Scanning.pdf (Accessed: 27 March 2019).
Ko, M. et al. (2019) ‘InFormed Ceramics: Multi-axis Clay 3D Printing on Freeform Molds’, in Robotic Fabrication in Architecture, Art and Design 2018. Cham: Springer International Publishing, pp. 297–308. doi: 10.1007/978-3-319-92294-2_23.
Lourenço, P. B. (no date) Analysis and restoration of ancient masonry structures Guidelines and Examples. Available at:
https://core.ac.uk/download/pdf/55604455.pdf
(Accessed: 27 March 2019).
Murphy, M. et al. (2017) ‘DEVELOPING HISTORIC BUILDING INFORMATION MODELLING GUIDELINES AND PROCEDURES FOR ARCHITECTURAL HERITAGE IN IRELAND’. doi: 10.5194/isprs-archives-XLII-2-W5-539-2017.
Quattrini, R., Pierdicca, R. and Morbidoni, C. (2017) ‘Knowledge-based data enrichment for HBIM: Exploring high-quality models using the semantic-web’, Journal of Cultural Heritage. Elsevier Masson, 28, pp. 129–139. doi: 10.1016/J.CULHER.2017.05.004.
Singh, R. and Nagla, K. S. (2018) ‘Improved 2D laser grid mapping by solving mirror reflection uncertainty in SLAM’, International Journal of Intelligent Unmanned Systems, 6(2), pp. 93–114. doi: 10.1108/IJIUS-01-2018-0003.
Wang, H. and Meng, X. (2019) ‘Transformation from IT-based knowledge management into BIM-supported knowledge management: A literature review’, Expert Systems with Applications, 121, pp. 170–187. doi: 10.1016/j.eswa.2018.12.017.
Xiao, Y., Zhan, Q. and Pang, Q. (2007) ‘3D Data Acquisition by Terrestrial Laser Scanning for Protection of Historical Buildings’, in 2007 International Conference on Wireless Communications, Networking and Mobile Computing. IEEE, pp. 5966–5969. doi: 10.1109/WICOM.2007.1464.
ROBOTIC SCANNING FOR ARCHITECTURAL DATA EXTRACTION, ANALYSIS AND VALIDATION is a project of IaaC, Institute for Advanced Architecture of Catalonia developed at Master in Robotics and Advanced Construction (M.R.A.C.) in 2018 by,
Students: Apoorv Vaish, Omar Geneidy, Owase Ansari, Sujay Kumarji
Faculty: Dir. Aldo Sollazzo, Jose Starsk Lara, Daniel Serrano