PLANET MACAD
Training a conditional generative adversarial network (cGAN) called pix2pix that learns a mapping from input PIXEL IMAGES to OUTPUT AERIAL IMAGES.
The present project aims to establish a novel workflow with the aim of bridging the gap between complex design and common users. Through the use of generative deep-learning algorithms and graphics programming, this interface provides the user with the opportunity to collaborate, without intermediates, in the design process of an imaginated landscape.
For our GENERATIVE MACAD PLANET PROJECT we build and train a conditional generative adversarial network (cGAN) called pix2pix that learns a mapping from input images to output images, as described in Image-to-image translation with conditional adversarial networks by Isola et al. (2017). pix2pix is not application specific—it can be applied to a wide range of tasks, including synthesizing photos from label maps, generating colorized photos from black and white images, turning Google Maps photos into aerial images, and even transforming sketches into photos.

In the pix2pix cGAN, you condition on input images and generate corresponding output images. cGANs were first proposed in Conditional Generative Adversarial Nets (Mirza and Osindero, 2014)

The architecture of our network will contain:A generator with a U-Net-based architecture. A discriminator represented by a convolutional PatchGAN classifier (proposed in the pix2pix paper). Note that each epoch can take around 15 seconds on a single V100 GPU.
We will define several functions that:
- Resize each
256 x 256image to a larger height and width—286 x 286. - Randomly crop it back to
256 x 256. - Randomly flip the image horizontally i.e. left to right (random mirroring).
- Normalize the images to the
[-1, 1]range.

- Each block in the encoder is: Convolution -> Batch normalization -> Leaky ReLU
- Each block in the decoder is: Transposed convolution -> Batch normalization -> Dropout (applied to the first 3 blocks) -> ReLU
- There are skip connections between the encoder and decoder (as in the U-Net).

- The generator loss is a sigmoid cross-entropy loss of the generated images and an array of ones.
- The pix2pix paper also mentions the L1 loss, which is a MAE (mean absolute error) between the generated image and the target image.
- This allows the generated image to become structurally similar to the target image.
- The formula to calculate the total generator loss is
gan_loss + LAMBDA * l1_loss, whereLAMBDA = 100. This value was decided by the authors of the paper.

- Each block in the discriminator is: Convolution -> Batch normalization -> Leaky ReLU.
- The shape of the output after the last layer is
(batch_size, 30, 30, 1). - Each
30 x 30image patch of the output classifies a70 x 70portion of the input image. - The discriminator receives 2 inputs:
- The input image and the target image, which it should classify as real.
- The input image and the generated image (the output of the generator), which it should classify as fake.
- Use
tf.concat([inp, tar], axis=-1)to concatenate these 2 inputs together.

- The
discriminator_lossfunction takes 2 inputs: real images and generated images. real_lossis a sigmoid cross-entropy loss of the real images and an array of ones(since these are the real images).generated_lossis a sigmoid cross-entropy loss of the generated images and an array of zeros (since these are the fake images).- The
total_lossis the sum ofreal_lossandgenerated_loss.

Note: The training=True is intentional here since you want the batch statistics, while running the model on the test dataset. If you use training=False, you get the accumulated statistics learned from the training dataset (which you don’t want).
- For each example input generates an output.
- The discriminator receives the
input_imageand the generated image as the first input. The second input is theinput_imageand thetarget_image. - Next, calculate the generator and the discriminator loss.
- Then, calculate the gradients of loss with respect to both the generator and the discriminator variables(inputs) and apply those to the optimizer.
- Finally, log the losses to TensorBoard.

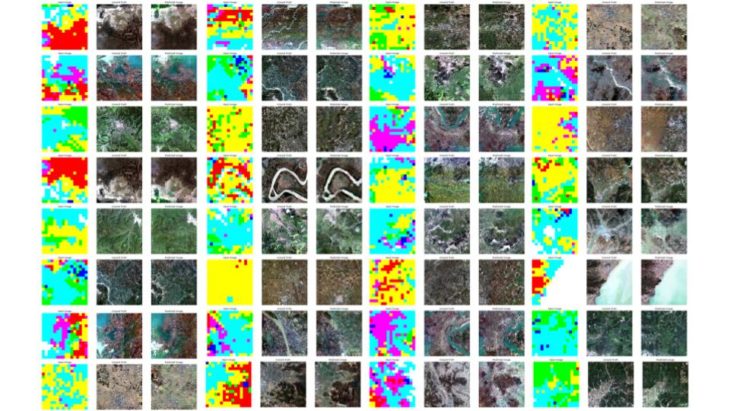
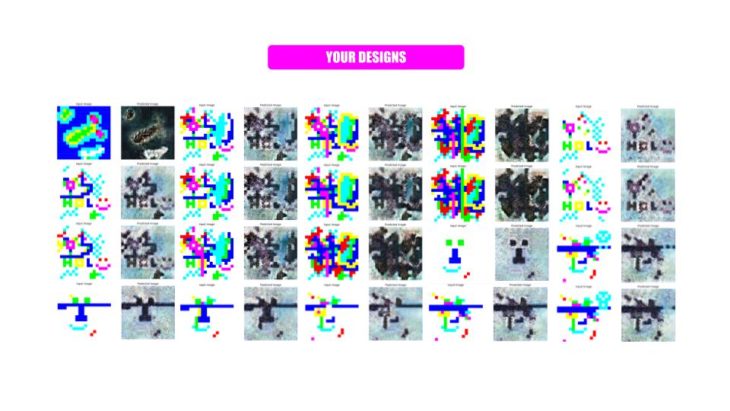


After getting our pokemons as species, we wanted to created a virtual 3D environment to inhabit. We took the data set and create from image sampler a mesh terrain with different heights based on the temperature predictions to get different climate environments. Ranging from sea level sets to mountain based geometries. We could generate not only the 3D terrain but also a map onto int showing the different temperatures within.

Afterward we try this grasshopper algorithm with 300 data trained images deploying all of them in 3D showing this tool cannot only be implemented as a images. Also we deploy the species independence to its climate environments having a simultaneous interactions within the terrain and its ways of inhabiting it.
After to see their interactions we deploy in AR as a tool to analyze the different outputs all together.. we introduced this tool as a visual which later can be taken as a tool of data visualization from machine learning to real environments. Opening the possibilities of introducing real case scenarios with real species and analyze their activities within the context. Within the video you can see as a test, two Pokémon fighting as part pf their natural interaction towards one another. Thank you very much for your attention, hope you enjoyed our presentation as much as we did developing our project
PLANET MACAD is a project of IAAC, Institute for Advanced Architecture of Catalonia developed in the Master of Advanced Computation in Architecture and Design 2021/22 by Students: Irene Martin Luque, Pablo Jaramillo Pazmino & Jacinto Jesús Moros Montañés Faculty: Oana Taut and Aleksander Mastalski