
image credits: Clemens Russ
Intro
The following project aims to recreate a series of simulations based on reinforcement learning agents to understand behaviours and patterns in or order improve an specific task in robotics and the construction industry.
Cleaning facades is a task that could be improved , not only for the several risks taken by the operators but also for the inefficency of the process to reach each window.
This research explore how to simplify each component to extract the necesary features and use an agent, simulating a cleaning machine that could be able to understand where should rove to reach all windows in complex buildings facadades.
Objectives
- Develop a simulation to train an reinforcemen learning agent which during the training process will learn how to reach and define a path to each window in complex facades.
- Simplify the building elements to extract the most relevant features and merge them with correspondent componets to train the agent.
- Run the simulation in a case of study, extract and save the most relevant outputs and plot results.
- Refine and compare goals defined to train the agent
Case of study
As case of study we choose MIT – Simmons Hall facade .
Inspired by the complex geometry of its facade. We deconstructed this geometry to get only the boundary of each facade and the coordinates position of each window. For this research we’ll not consider physical properties as features. Like materials, windows geometry or depth.

image credits: MIT-Simmons-hall – Steven Holl
Facade deconstruction process consist in unfold each side and get windows center to extract the coordinates (x,y). Then defined a boundary threshold with a divided polyline where we’ll get coordinate points as well.
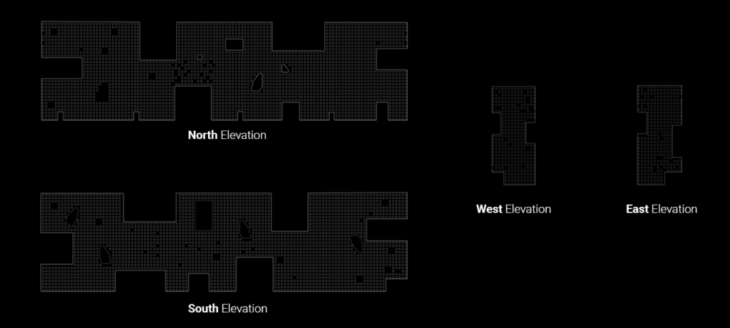
fig 3. Simplified geometry Elevations
The following steps determined the main process for this research.
First we explore the building facade (geometrical features extractions / coordinates). Then use them as inputs for each component to build a 2d game learning engine, where we will run the simulation to train our agent. Then we proceed to save relevant outputs and finally plot the
data.
Reinforcement Learning
Reinforcement learning problem is meant to be a straightforward framing of the problem of learning from interaction to achieve a goal.
Q-learning finds the best optimal policy in the sense of maximizing the expected value of the total rewards over succesive steps.
The simplified definition which help me to undertand is learn by experience.
Concepts
Environment:
The thing it interacts with, comprising everything outside the agent.
Agent:
The decision maker.
Rewards
A numerical value.
Actions:
Options selected by the agent based on the environment interaction.
State:
Probabilities to select an action in order to improve performance.
Episode:
Simulation timeframe.
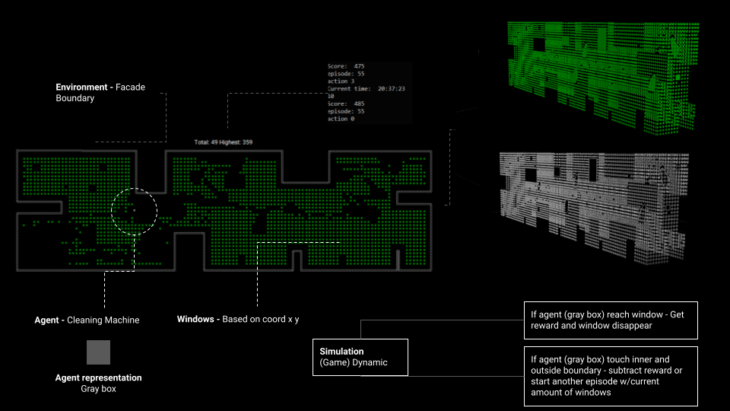
fig 4. Geometry Setup
Setup and Rewards
Rewards:
agent touch green window 10
agent comes closer to green window 1
agent goes away from green window -1
agent comes closer to boundary -3
agent goes away to boundary 1
agent dies (hit wrong window or wall) -100
Actions:
agent moves up 0
agent moves right 1
agent moves down 2
agent moves left 3
State:
Window is above agent 0 or 1
Window is on the right of agent 0 or 1
Window is below agent 0 or 1
Window is on the left of agent 0 or 1
Boundary directly above agent 0 or 1
Boundary directly on the agent 0 or 1
Boundary directly below agent 0 or 1
Boundary directly on the left 0 or 1
Agent direction == up 0 or 1
Agent direction == right 0 or 1
Agent direction == down 0 or 1
Agent direction == left 0 or 1
Training DQN Learning
Now, on for this test of the training process we se how the windows are populated during the first episode. Then by the last episode de amount of windows decrease, which means that the agent is learning how to get rove to the closest window and incrementally reach all windows during a considerable amount of episodes.
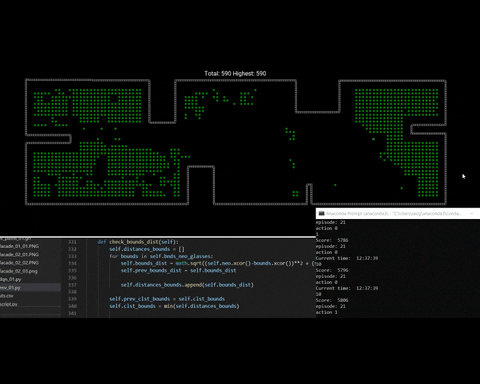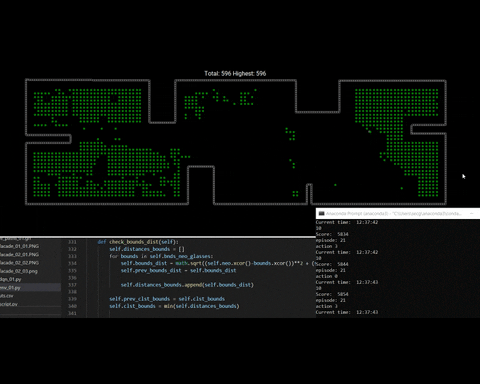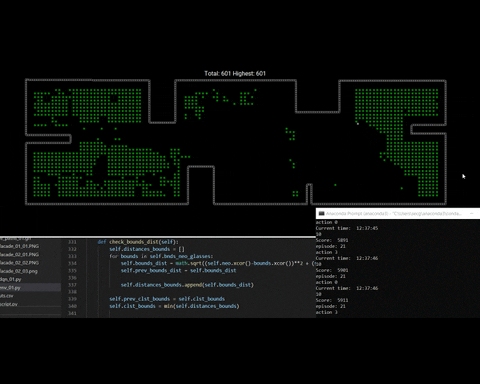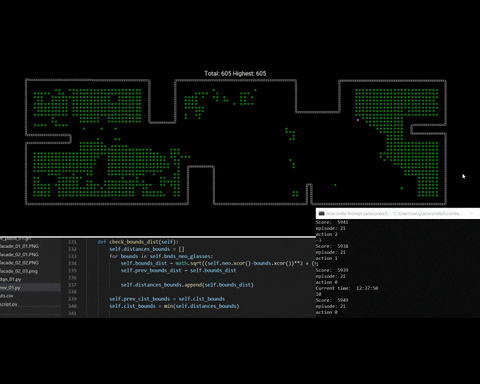
fig 5. Training process
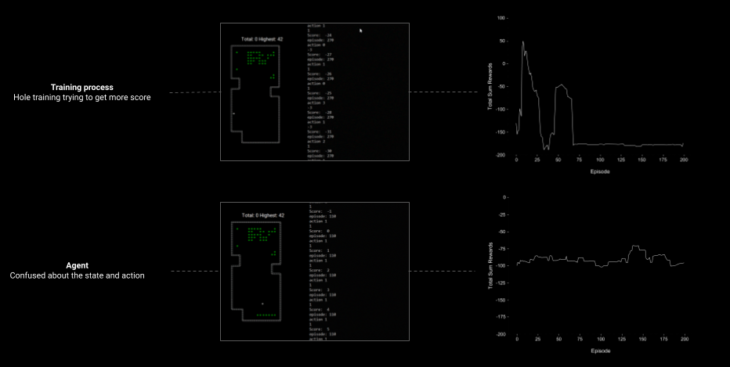
fig 6 & 7. Failures and graphs
Results
The following results are based on the episode with best performance during training process.

fig 8. Plots
And then here the paths defined during the simulation by the training process.

fig 9. Pathfinding
Reproducibility
Is up to us to defined the Dynamic of the game or simulation.
For the first test we experience start every episode with the last amount of windows left by the agent.
We could change the goal to optimize the training simulation by adding all the boxes again when the episode ends.
We do this to train the agent in order to reach the windows all at once.
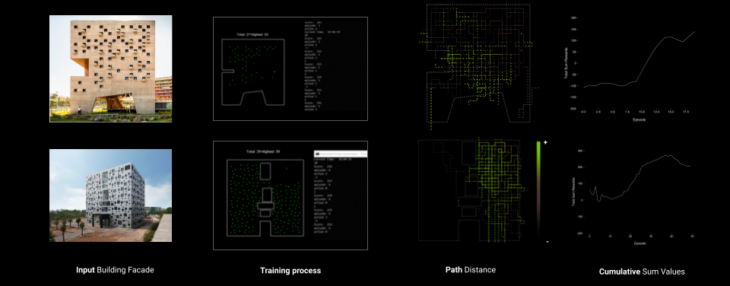
fig 10. Reproducibility
There is an interesting opportunity to reproduce the same process in another complex facades. Like these examples trained with the 2nd dynamic simulation setup.
Is right to mention that this test only works to find 2d coordinates.
Still missing another important and relevant features like windows geometry and depth representation. Something that could be explore with libraries that could help to understand and build 3dimensional environments and apply physics in order to have more realistic experiences during the training process.
Conclusion
To conclude this research. An update of current cleaning systems,
could optimize performance and reduce risks for operators during cleaning windows on buildings.
However in this research we just tackled a very early state to understad path finding based
on an agent’s behaviour in complex facades.
References:
Reinforcement Learning: An Introduction. Richard S.Sutton and Andrew G- Barto
en.wikipedia.org/wiki/Deep_reinforcement_learning
jonathan-hui.medium.com/rl-introduction-to-deep-reinforcement-learning-35c25e04c199
towardsdatascience.com/snake-played-by-a-deep-reinforcement-learning-agent-53f2c4331d36
www.cs.toronto.edu/~vmnih/docs/dqn.pdf
github.com/NariddhKhean/Grasshopper_DQN/-blob/master/README.md
Pathfinding for Automated windows cleaning systems in Complex Facades is a project of IAAC, Institute for Advanced Architecture of Catalonia developed at MaCAD (Masters in Advanced Computation for Architecture & Design) in 2022 by Student: Salvador Calgua, and faculty: Gabriella Rossi.