“ornament and crime”
predicting solar irradiation values for self shading brick surfaces

abstract
problem statement: By 2050 about 70 % of the world’s population will live in cities. Whilst global temperatures are rising towards +4°c, building facades are a main contributor to the urban heat island effect within cities. Therefore increasing passive measures such as shading, reflectivity, thermal massing, adiabatic cooling can make strong contributions using our world resources more responsibly.

Our research focused on predicting the solar irradiation value (kWh/m²) on the self shading brick facades.For this process, we have parametrically generated datasets with 3.600 – 10.000 datasamples, of a brick facades 50 x 50 cm and with fixed brick measures of L=25cm , W=12cm, H=6cm. The dataset geometries were generated in grasshopper for rhino, using the ladybug extension for solar irradiation analysis, kohonen maps extension for normalizing the data and the random components and genetic solver galapagos native components for the generation process. The dataset was based on numerical values compiled of 12 different features such as:
- orientation, displacement_of_brickrows_in_y (9 features) total_solar_irradiation, solar_irradiation_per_surface, total_surface_area.
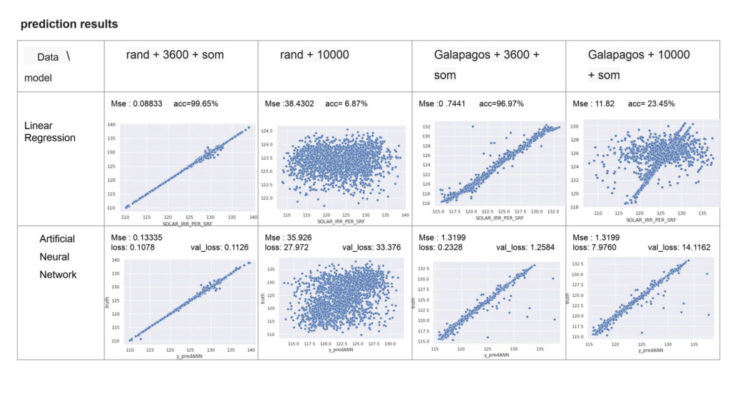
For prediction of the solar radiation per surface we’ve used linear regression and trained an ANN regression modell in python. our explorations were centered around data curation, feature selection and the effects of size and distriubtion on the prediction.
research objectives:
- Our research focuses on the self shading effects of brick facades by predicting their solar irradiation value (kWh/m²).
- Investigate the geometrical relationships (such as angle, noise, surface areas) and the solar irradiation value.
- Make a contribution to cooling down cities + increase passive measures in architecture.
- Contribute to a paradigm shift of ornaments in architecture from decoration to contributor.
pseudo code:
the dataset normilization through self organizing maps has turned out to be a crucial part in our experiment and was incorporated into our pseudo code in a second step. please refer to “process + first results” section. below.
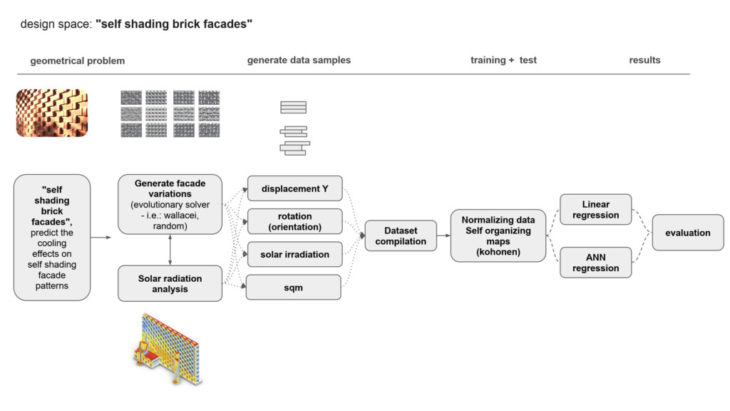
algorithm + features:
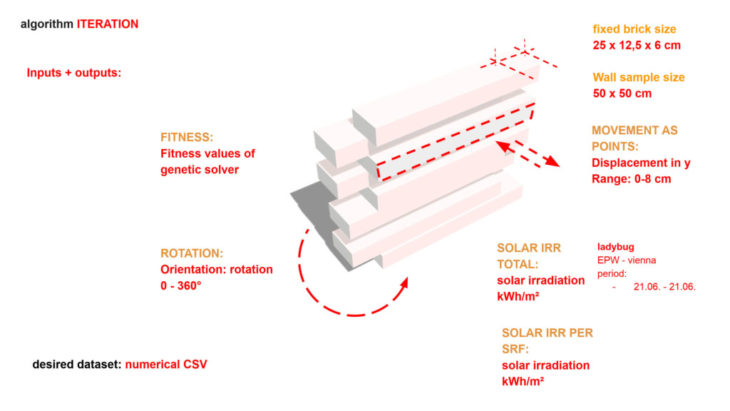
process + first results:
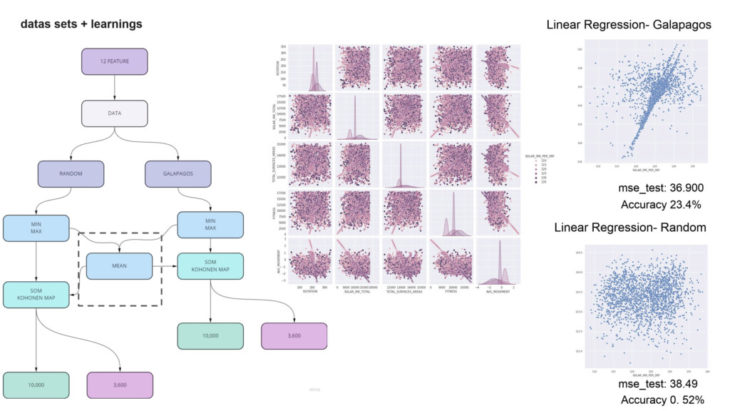
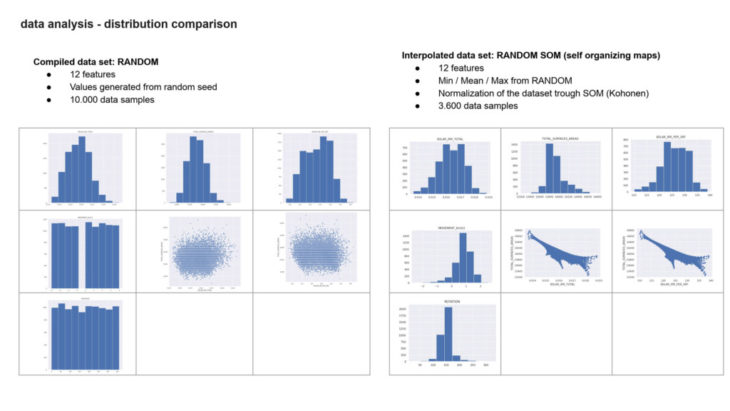
first dataset explorations have showen, that genetic solvers are creating an inherent bias for the prediction. although we created several datasets from grasshopper galapagos, iterating towards minimum and maximum, the distribution was turned out unsatisfactory for our experiment. however, this has led our approach towards normalizing the datasets from our maximum, mean + minium values generated from the galapagos dataset, using self organizing maps (SOM) – in this case KOHONEN maps in grasshopper for rhino. through the normalization process we were able to generate a well distributed dataset of 3600 data samples.
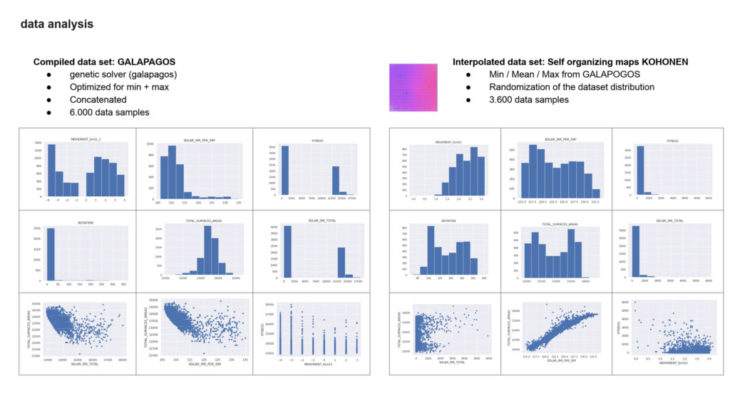
dataset + learnings:
the dataset size turned out to be sufficient with about 3600 data samples. whilst explorations with bigger datasets about 10.000 datasamples seemed to decrease the learning accuracy again, which points out the limitations of the normalization through SOM for this particular experiment. this means, only one type of algorithm was trained within the dataset, therefore further samples with different types of facade patterns are up to be explored within the next experiment.

one important learning from our different dataset explorations was to increase the diversity of the dataset by implementing min, max and especially several mean values whilst creating the kohonen normilization for it. initial explorations with a dataset of 10.000 datasamples generated throug min and max values only have shown to mislead the dataset and the modell. therefore the implementation of mean values and reduction of dataset samples has turned out to be essential.
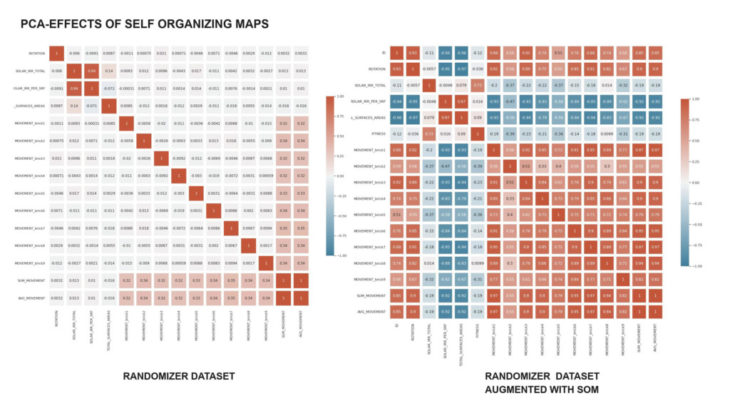
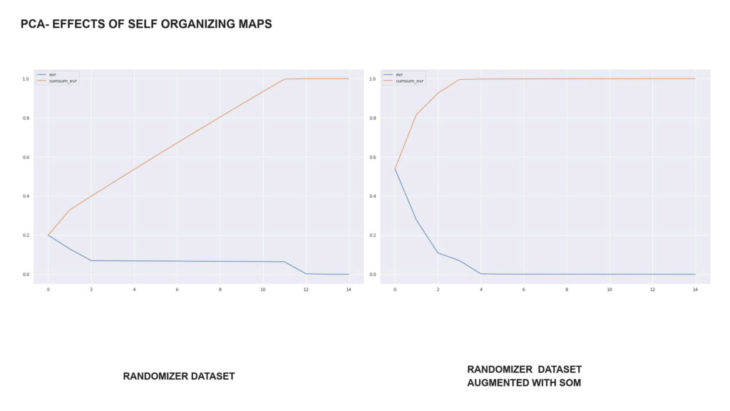
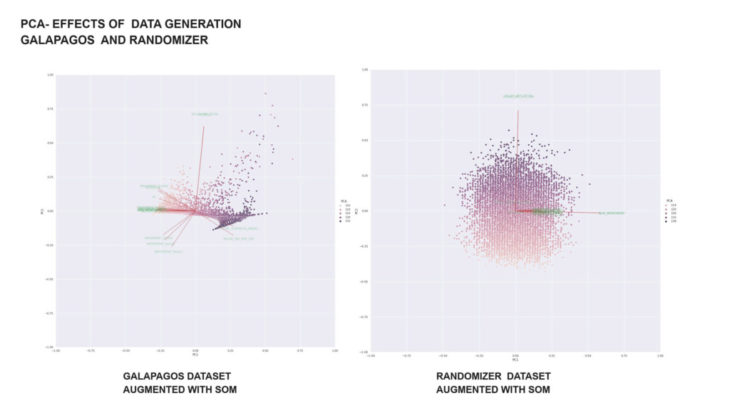
principal component analysis:
the PCA clearly stated the lack of correlation and diversivication within the initial dataset, whilst the heatmap (right) of the kohonen maps normalized dataset shows high correlation values.
modell architecture:
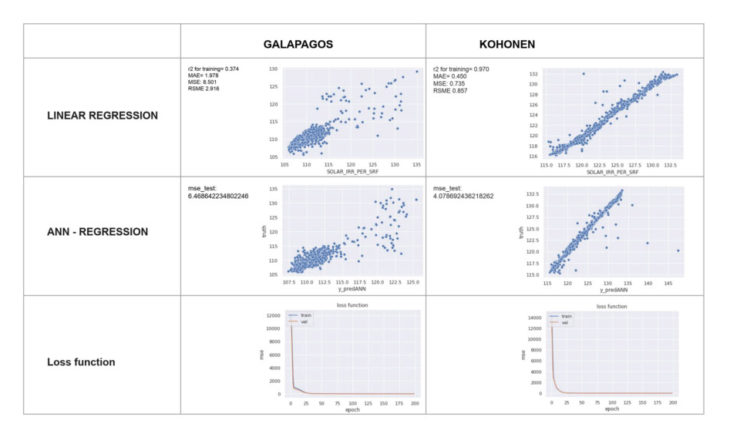
for our experiment we’ve used linear regression + ANN regression as prediction method. we’ve chosen a lean approach to our modell architecture, which gave promising results after 200 epochs already.
Model: “sequential_10”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_30 (Dense) (None, 32) 416
dense_31 (Dense) (None, 16) 528
dense_32 (Dense) (None, 1) 17
=================================================================
Total params: 961
Trainable params: 961
Non-trainable params: 0
_______________________________
test + train:
data analysis – distribution and comparison:
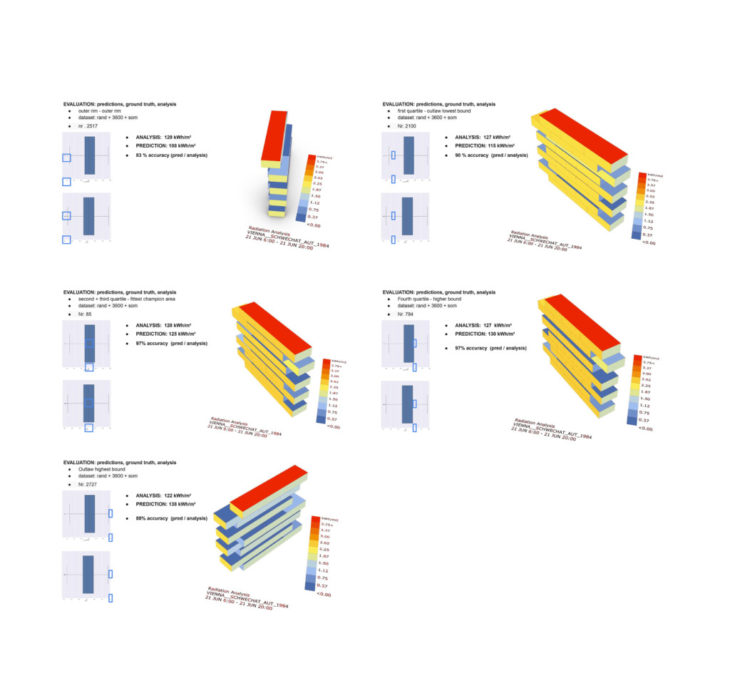
geometry and evaluation:
the boxplots showed the main distribution of the dataset. the prediction accuracy behaved like a bell curve decreasing – showing 88% accuracy – towards the outer boundaries, whilst increasing towards the second and third quartile, where 50% of our dataset was mostly located, towards 98 % accuracy.
“ornament and crime” predicting solar irradiation values for self shading brick surfaces is a project of IAAC, Institute for Advanced Architecture of Catalonia developed at the Masters in Advanced Computation for Architecture and Design in 2022 by Daniyal Tariq + Clemens Russ, and Faculty: Gabriella Rossi, Hesham Shawqy