INTRO TO PHYSICAL COMPUTING
Seminar faculty: Angel Muñoz
Physical Computing is an approach to learning how the world communicate through computers that starts by considering how humans and the environment works physically.
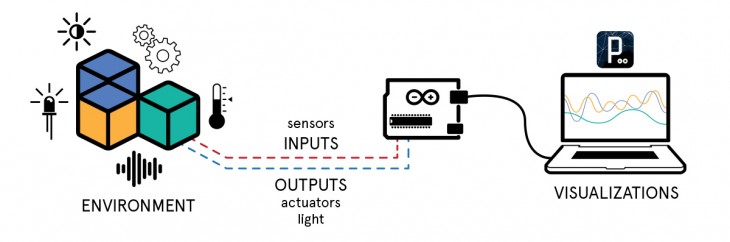
It means building interactive physical systems by the use of software and hardware that can sense and respond to the analog world.
In the broad sense, physical computing is a creative framework for understanding human beings’ relationship to the digital world.
We have the sensors to capture the real world, and very simple computers, called microcontrollers like Arduino, that read sensors and convert their output into data. Then we can respond to this inputs through actuators like motors, lights or any kind of electronic device.
Physical computing takes a hands-on approach, which means that you have to spend time building circuits, soldering, writing programs, building structures to hold sensors and controls, and figuring out how best to make all of these things relate to a humans expression or environment conditions.
In summary, physical computing is about making things talk.