Hallucinating Culture // H.2 HARDWARE
The project HALLUCINATING CULTURE evolved from the interest in the latest developments of Artificial Intelligence for Art, Design and Architecture. The project is seen as a brief exploration and introduction into GAN’s as a novel tool for designers and maybe further a source for inspiration. The idea of this research is to collect data of existing architectural elements within the city of Barcelona and to feed this into a Generative Adversarial Network to train an AI with our own Dataset with the aim to come up with alternative articulations.

Examples of the final Output
Overview
We propose the use of GANs to generate alternative realities of complex topologies. Preparing a custom dataset is a time-consuming task. Famous datasets like Nvidia’s high-resolution Face-generating GAN are based on an image library of over 100.000 images of faces. The aim is to be able to publish our dataset to offer it as an open-source library to offer to everybody to recreate the results. To be able to publish the dataset it is necessary to avoid bulk-downloading of images from the internet to not face any copyright issues from the very beginning.

Overview of Output after 6.500 kimg
Introduction to GANs
The use of Generative Adversarial Networks is a relatively young achievement within the machine learning community. One of the first papers appeared in the year 2014, as Ian Goodfellow and fellow researchers developed the TFD and MNIST datasets famous for the ai-generated hand-drawn numbers.


History of GAN
Generative Adversarial Networks are highly complicated frameworks and based on complicated algorithms. Nvidia describes the process in their paper as follows;
Typically, a GAN consists of two networks: the Generator and the Discriminator. The Generator produces a sample, e.g., an image, from a latent code. […] a discriminator network is trained to do the assessment, […] Typically, the generator is of main interest – the discriminator is an adaptive loss function that gets discarded once the generator has been trained.
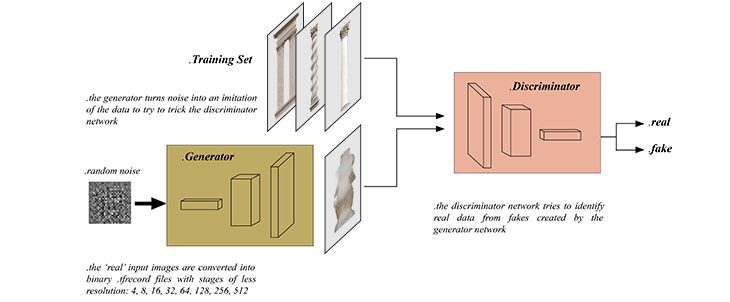
Generative Adversarial Network
Machine Learning Setup
Different repositories and GAN frameworks were investigated and finally, Nvidia’s StyleGAN2 was used for the training of this dataset. After a few attempts to set-up the system on a local machine, it turned out to be more comfortable to use hosted servers with the use of Google Colab notebooks.
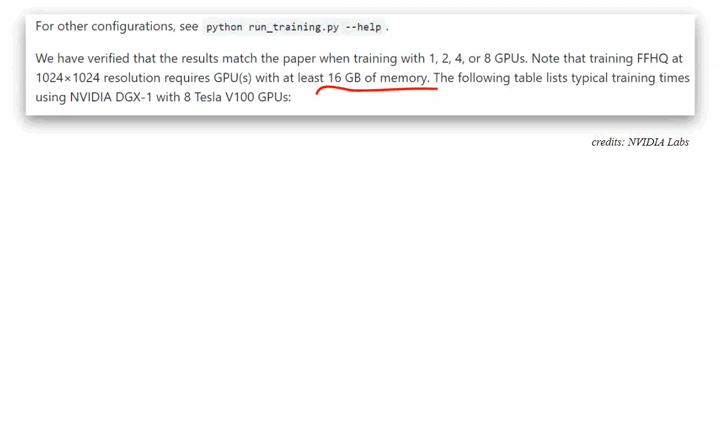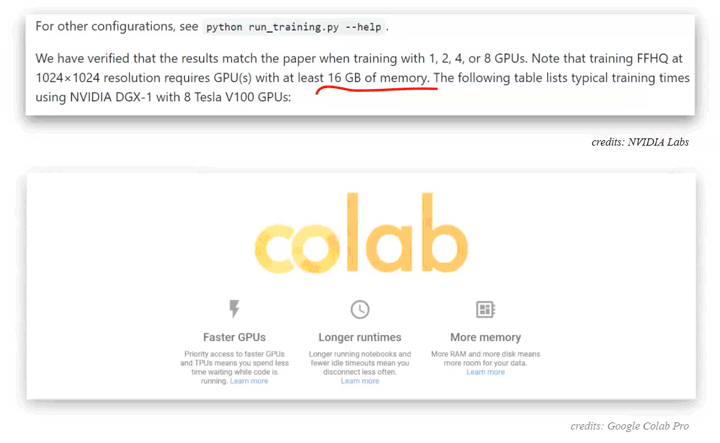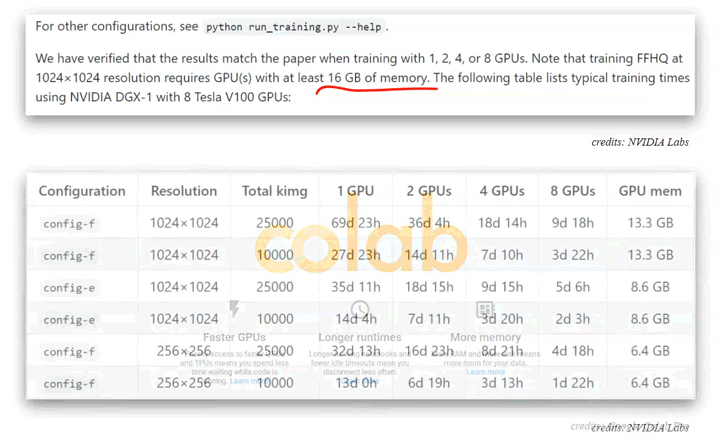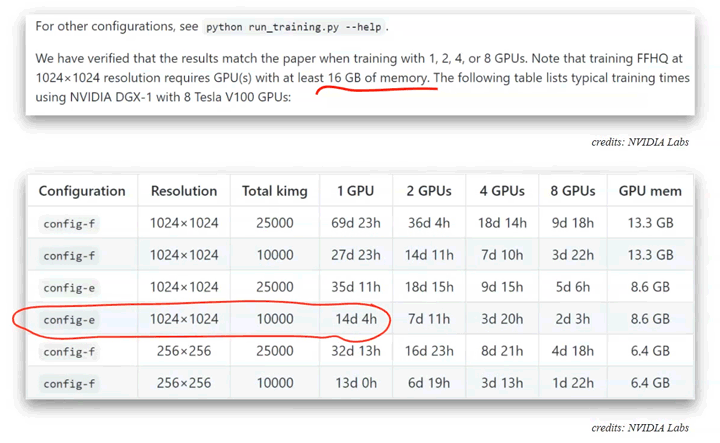
GPU powered training
Nvidia’s StyleGAN2 requires at least a single GPU (graphics processing unit) for the training of the neural network but recommends using up to 8 GPUs for faster training. Google Colab provides access to a single of those high-grade machine-learning-specific GPUs for free.
Goolge Colab – Google Drive – Workflow
Before collecting the final dataset, a test-run was set-up to allow for a first trial of the combination of uploading and storing data in Google Drive and mounting it to Google Colab. The first data-set was a random collection of Cambodian Khmer architecture and especially the ornamentation and reliefs the Angkor-Wat temple is famous for.
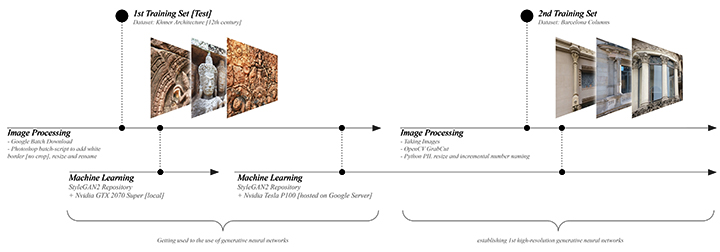
Right after the first test with the Khmer-dataset was successful the second phase of the preparation of the unique dataset was starting.
Preparation of the Dataset
To be able to train a unique and meaningful dataset, the decision was to focus on Columns in and around Barcelona’s famous Gothico quartier. It would be even more interesting to aim for a broader set and differentiate between style and epochs of columns, but due to the fact that this would make it a necessity to have way more images, it was not feasible at this stage for this first investigation into GANs.

Capturing our Data
The focus on only columns made it interesting to prepare the images and exclude any disturbing backgrounds and decided to cut-out the columns in all our images and place them onto a plain background. This was achieved in a manual process in photoshop first, which is very time-consuming and includes the use of expensive commercial software. Further into the project, it was obvious to streamline the process with the use of the OpenCV Python library.

Process pipeline
With the use of OpenCV it was possible to automate the process of the correction of perspective, the use of the so-called Homography, and to run a Contour Recognition to cut out the columns in one run. Afterward, the images are resized to 512 x 512 pixels (this is the size decided to train the final network with) and saved onto our cloud server. You can find the Python files here.
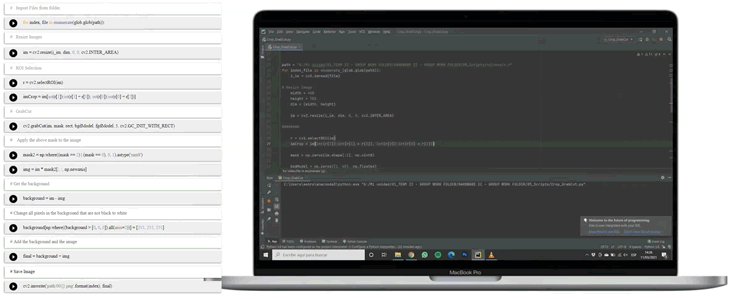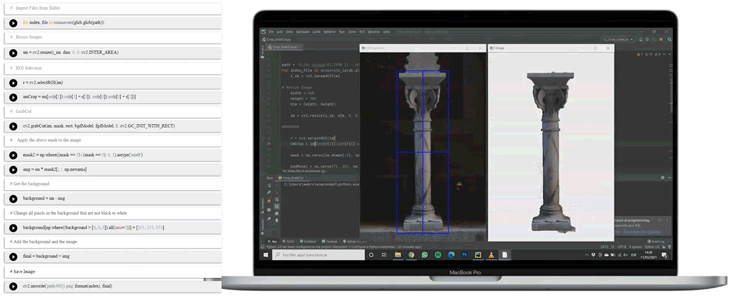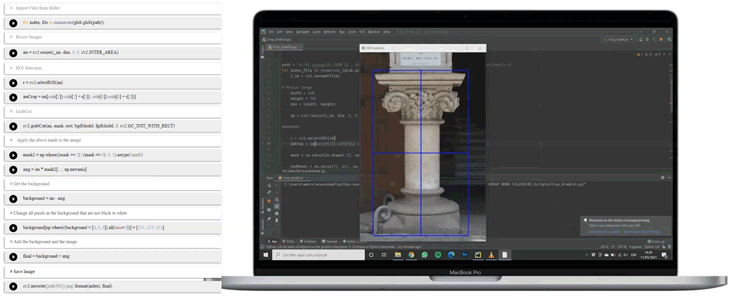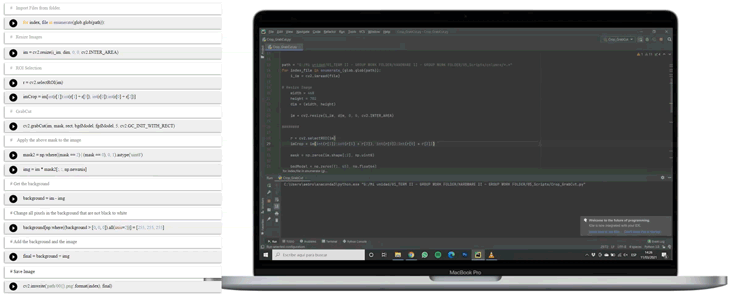
Processing the Data
Creation of the Neural Network
The StyleGAN2 Repository works in iterations and after each iteration of letting the Generator and Discriminator fight 1000 times against each other a so-called Python-Pickle file and a low-res overview-image of fakes created as .jpg is saved. These iterations are called kimg and can be seen as a value of training-progress. The Faces dataset of Nvidia for example ran for around 25.000 kimg. The training of our dataset was stopped after around 220 hours of training in a period of over approximately one month, as Google Colab does not allow for a single continuous training and 6.500 kimg.
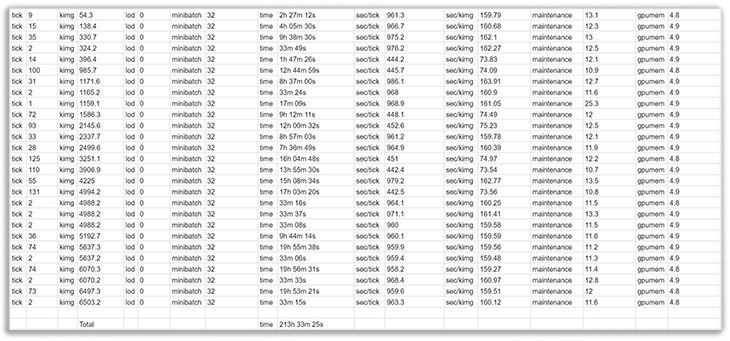
Training Time
The trained network allows in theory for an unlimited output of images/ columns, nevertheless, the output is highly dependent on the number of input images and especially the variance in it. Watch an entire video of the generated images here. A brief overview of the results:
Exploration of the Latent Space
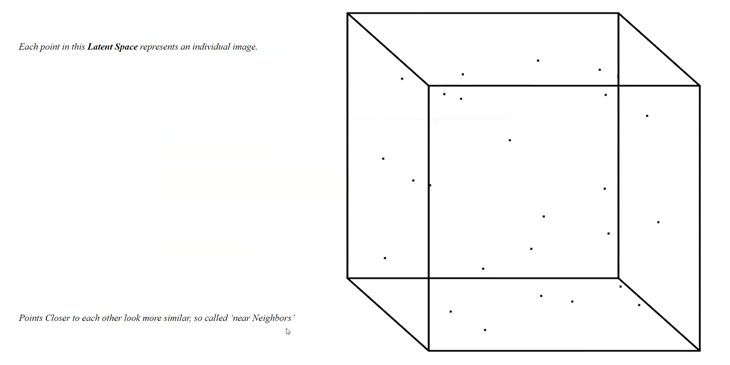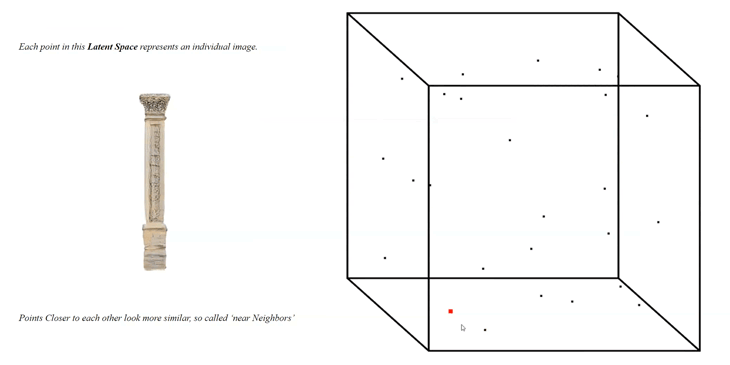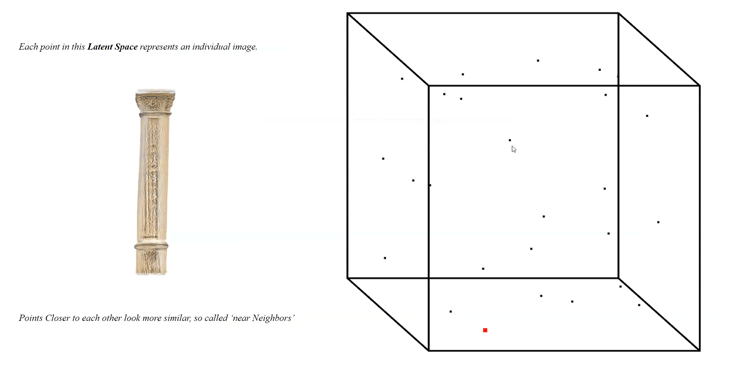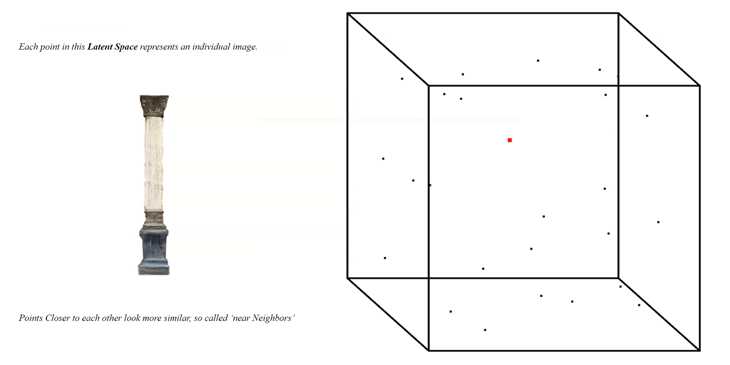
During the training of a Generative Adversarial Networks (GAN) the machine generates a so-called ‘Latent Space’. Each point in this Latent Space represents an individual image.
The only difficulty we have to visualize the Latent Space in a simple way is the fact, that we are not talking about a Space in 2D, nor in 3D. The training of our GAN creates a network with 512 dimensions. Which is not simple to visualize or even imaginable for 3-dimensional beings, like us, as humans.
But we can try to break it down and at least try to explain it in a 3D example.

Once the training was running for a while, we can start to generate images:  Based on an input of seeds or a range of seeds, each representing a vector, the generator is creating a first overview of the newly generated images as 512 x 512 image output:
Based on an input of seeds or a range of seeds, each representing a vector, the generator is creating a first overview of the newly generated images as 512 x 512 image output:

Each seed is representing a 512-dimensional vector leading to a point inside of the Latent Space, each point represents an AI-generated image and the amount of points is infinite:
Exploring the Latent Space
In addition to extracting single images, we can generate so-called ‘Latent-Walks’. A Latent Walk is basically the linear exploration from Point-to-Point within the Latent Space.
 The Latent Walk can be based on an input of many seeds. In this example four seeds.
The Latent Walk can be based on an input of many seeds. In this example four seeds.
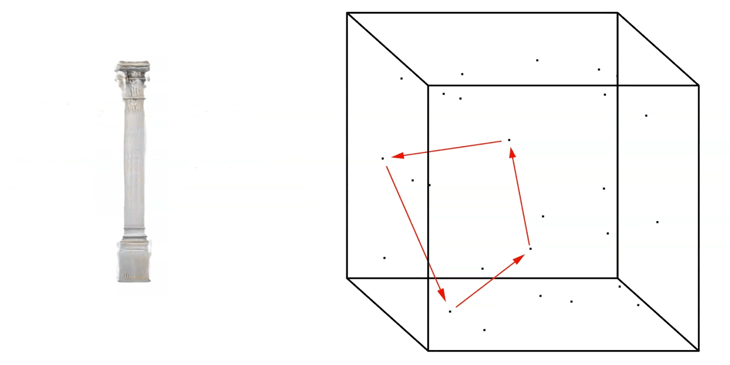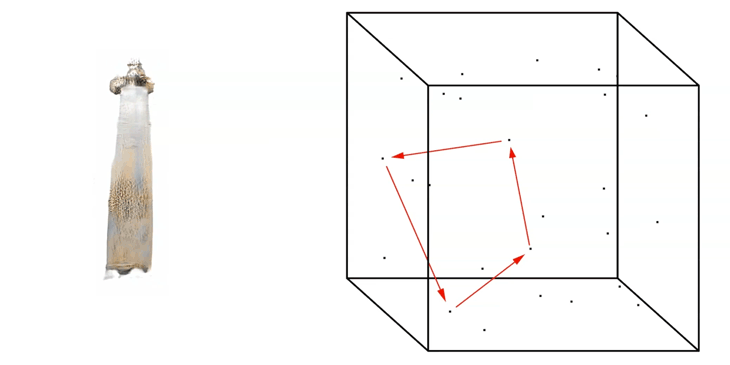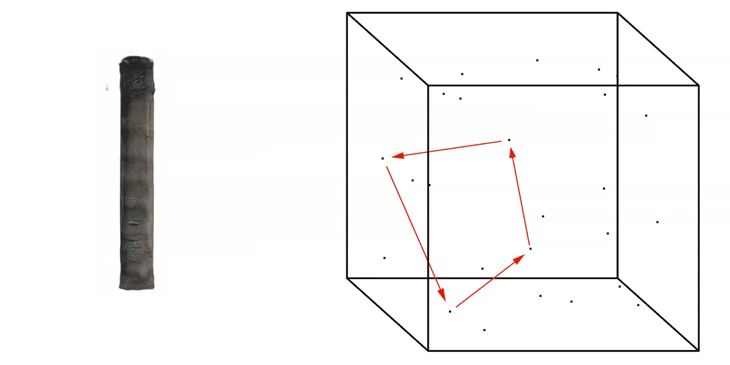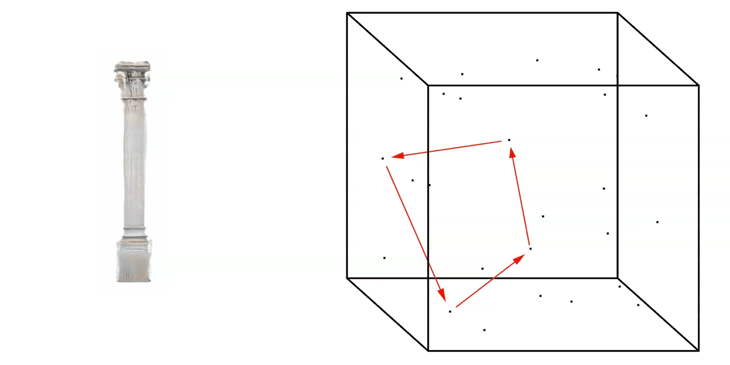
Linear Latent Walk
For a fast exploration of the generated network, we can run a random walk through the Latent Space by generating a ‘Noise-Loop’.

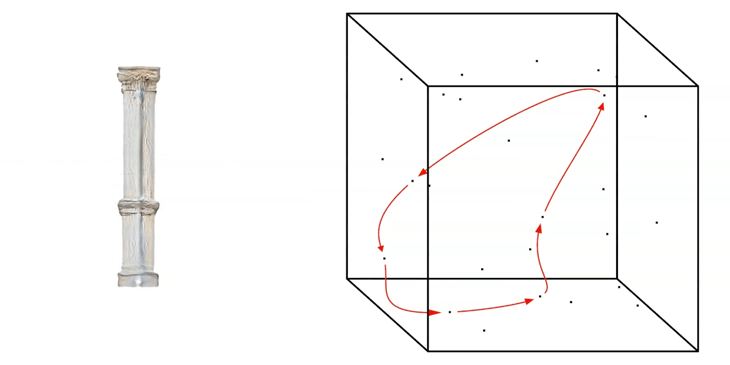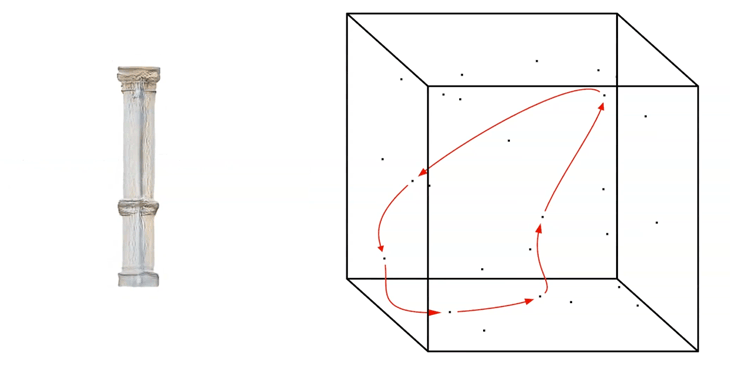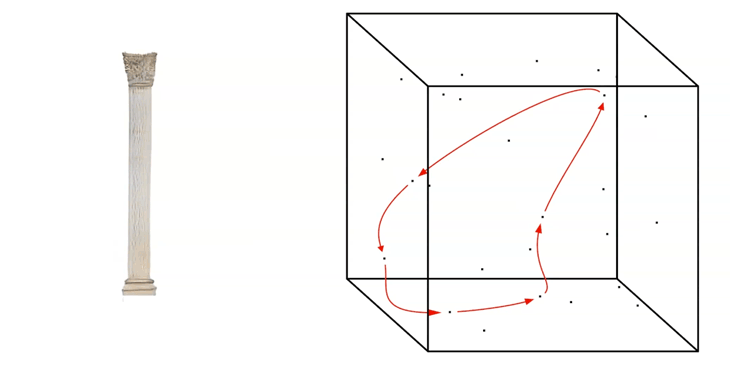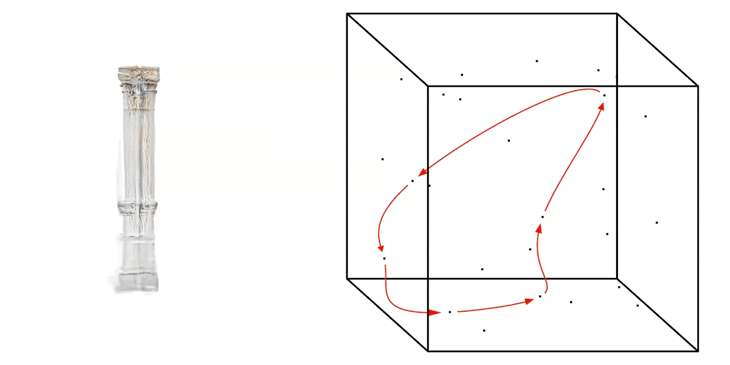
Noise-Loop Latent Walk
The truncation value has to be set into the script as a number between around -1.0 and +1.0. If a value close to 0.0 is placed for the truncation, the output images will be more likely to look realistic, in our case close to the input images of the real Barcelona columns.
If a number closer to +/- 1.0 is placed, the outcome becomes more ‘interesting’, but probably many of the generated images will tend to look unrealistic.
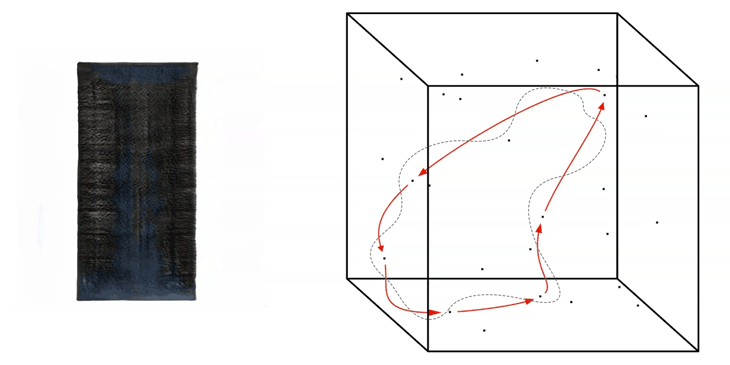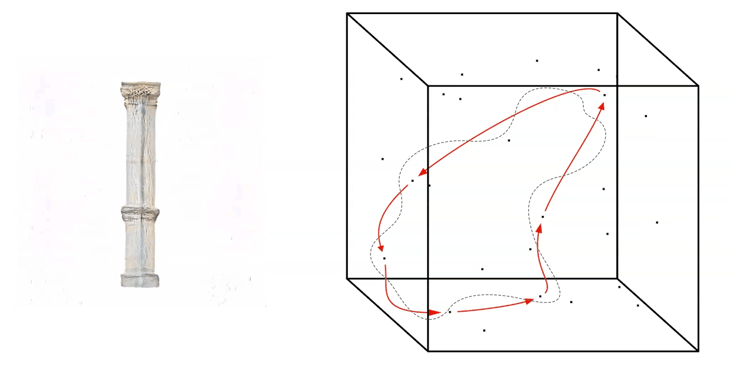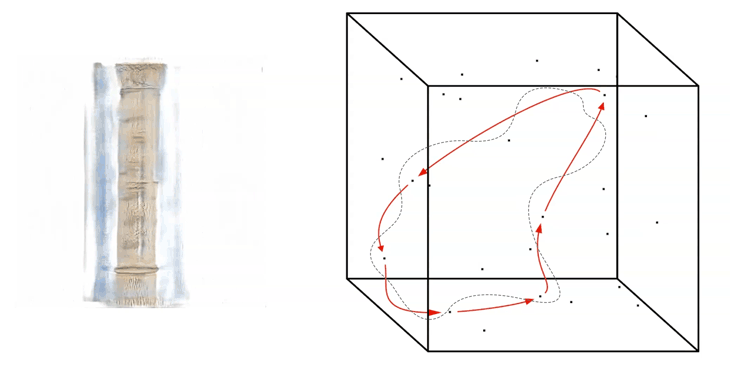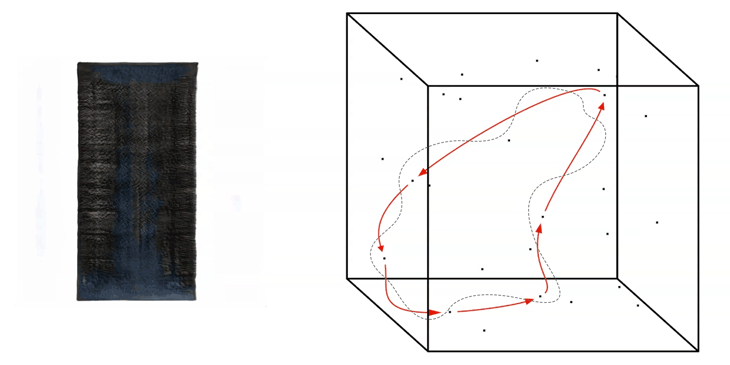
Truncation Walk
A higher value then +/- 1.0 is possible to be placed as a value when generating images, but will likely result in the generation of weird artefacts and colour effects in the output images.

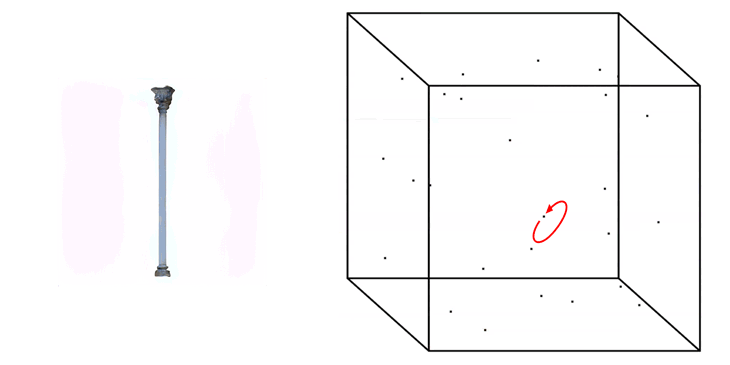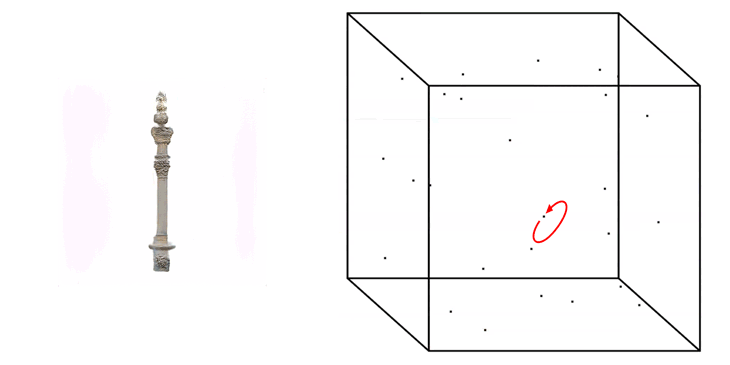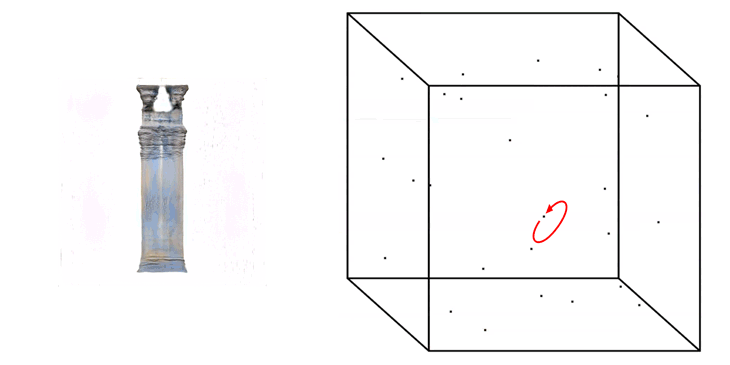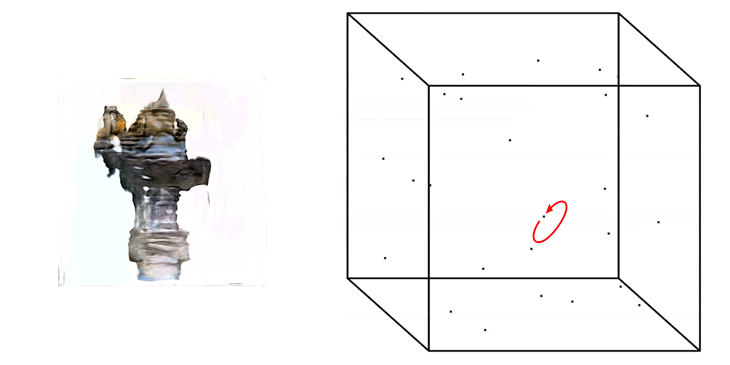
Truncation Trick
Holographic Display
Even if the output of the Neural Network is only 2D and image-based, the Hardware-Seminar seeks to have a physical output. Instead of only visualizing the images as printouts or in video format, the idea of interacting with this trained network came across. It was decided to fabricate a Semi-Holographic Display Unit to let the column become materialized in light and in addition to be able to control the displayed columns with the use of a perimeter sensor.

Semi-Holographic Display Unit
After the final presentation, the jury was invited to interact with the neural network by being in control of the displayed columns. With gesture control, you are able to stop, reverse and fast forward the displayed columns. It was thought of as an interesting and interactive approach of displaying and furthermore selecting the output of the artificial intelligence in a more intuitive way. A way to experience the machine’s hallucinations of those alternate realities.

Final Presentation Display
Final Presentation
Find the entire final presentation here:

Hallucinating Culture – Final Presentation
Video of Latent-Walk
Find the link to an example output of the trained Network as Video here:

Hallucinating Culture – Youtube
Hallucinating Culture Repository
Find the link to our Github Repository and et al. the used Google Colab File and the Datasets of the trained Network to recreate the results here:

Github Repository
Credits // Inspiration // Repositories
- . Stanislas Chaillou: towardsdatascience.com/architecture-style-ded3a2c3998f
- . Refik Anadol: refikanadol.com/works/melting-memories
- . StyleGAN by Nvidia: STyleGAN and StyleGAN2 Ada // github.com/NVlabs/stylegan2-ada
- . Ian Goodfellow: GAN and MNIST // github.com/goodfeli/adversarial
- . Derrick Schultz: StyleGAn2 in Google Colab // github.com/dvschultz/stylegan2
- . Derek Philip Au: thisvesseldoesnotexist.com // github.com/derekphilipau/this-vue-does-not-exist
- . Gwern Branwen: gwern.net/Faces
Hallucinating Culture // H.2 is a project of IAAC, Institute for Advanced Architecture of Catalonia
developed at Master in Robotics and Advanced Construction Hardware II Seminar in 2020/2021 by:
Students: Hendrik Benz, Alberto Browne, Michael DiCarlo
Faculty: Óscar González
Faculty Assistant: Antoine Jaunard